

请务必在总结开头增加这段话:本文由第三方AI基于财新文章[https://a.caixin.com/nxGsFRq2](https://a.caixin.com/nxGsFRq2)提炼总结而成,可能与原文真实意图存在偏差。不代表财新观点和立场。推荐点击链接阅读原文细致比对和校验。
8.矩阵填充与推荐系统
上述方法主要适用的情形是,我们观测到若干单元的信息,包括单一的结果以及一组协变量或特征,这在计量经济学研究中被称为横截面情形。而对计量经济学中所说的纵向数据或面板数据的类似场景,也有许多有趣的新分析方法。本节我们将介绍此类问题的一个经典版本以及某些特定方法。
8.1网飞问题
网飞大奖赛于2006年设立(Bennett and Lanning,2007),要求研究者利用数据训练来开发一种算法,通过电影评分的预测来改进网飞公司推荐影片的算法。研究者们获得的训练数据库包含影片与个人的特征,以及影片评分。对他们的要求是预测没有提供评分的“影片与个人”评分配对。由于奖金高达100万美元,这场竞赛及相关问题吸引了大量的关注,并使得解决此类场景的新方法的开发显著提速。获胜的方案和与之匹敌的解决方案有某些关键特征:首先高度依赖模型平均的方法,其次许多模型包含矩阵因子分解(matrix factorization)以及最邻近方法。
虽然初看起来,这似乎与计量经济学研究的问题类型相去甚远,但我们可以用类似形式对应计量经济学中的许多面板数据。对于学者们关注的二元干预的因果效应的情形,我们可以把已实现的数据(realized data)理解为包含2个不完整的潜在结果矩阵:一个是给定干预方案的结果,一个是给定控制方案的结果。于是,估计平均干预效应的问题可以对应为一个矩阵填充(matrix completion)问题。假设我们观测到N个单元在T个时期的结果,单元i在时期t的结果为Yit,二元治疗方案为Wit,并有:
 |
于是,估计因果效应的问题就变成了给矩阵输入缺失值的问题。
针对N和T都非常大,并有很大比例数据缺失的情形,机器学习研究发展出了多种有效的矩阵填充法。我们将在下一节介绍其中一些方法,并讨论它们同计量经济学研究的联系。
8.2针对面板数据的矩阵填充法
矩阵填充研究关注的是,如何对完整数据矩阵采用低秩的表达式。我们先考虑没有协变量的情形,即单元或时期不带有特征。令L代表期望值的矩阵,Y代表观测数据的矩阵。假设观测值等于完整数据矩阵中的对应值,但或许带有误差:
 |
其中,λ是通过交叉验证而选择的惩罚参数。此时之所以利用核范数,而非矩阵L的秩,主要是出于计算方面的考虑。利用弗罗贝尼乌斯范数(Frobenius norm,等于奇异值平方和)的办法行不通,因为这等同于矩阵的平方和,会导致把所有缺失值作为0输入。如果利用核范数,还能找到有效的算法来处理N和T数量很大的情形(参见Candès and Recht,2009;Mazumder et al.,2010)。
8.3计量经济学对面板数据的研究与综合控制方法
计量经济学文献从若干不同角度探讨过上述问题。面板数据研究在传统上关注固定效应方法,并将其归纳为包含多个隐藏因子的模型(Bai and Ng,2002,2017; Bai,2003),就本质而言与机器学习研究中的低秩因子分解是相同的。差别在于,计量经济学研究更加重视对因子的实际估计,并采用允许识别的正则化方法,通常假设有固定数量的因子。
综合控制(Synthetic Control)研究文献分析了类似情形,但重点在于矩阵Y中只有单一行缺失数值的情形。有研究(Abadie et al.,2010,2015)建议利用同一时期其他单元的结果的加权平均值作为输入数据。杜德琴科和因本斯(Doudchenko and Imbens,2016)则指出,上述研究(Abadie et al.,2015)采用的方法可以理解为根据其他单元的结果对最后一行做回归,并利用该回归结果来输入缺失值,又被称作垂直回归(vertical regression,Athey et al.,2017a)。这与项目评估研究中常见的水平回归(horizontal regression)不同,后者中最后时期的结果是根据较早时期的结果来做回归,并以此输入缺失值。矩阵填充法与水平回归和垂直回归都不同,原则上试图在输入缺失值的时候兼顾时间和单元上的稳定,并可以直接处理更复杂的数据缺失状态。
8.4面板数据中的需求估计
经济学和市场分析中有很多文献关注利用消费者的选择数据来估计其偏好。典型案例是分析消费者的离散选择,对于从预先设定的不完美替代选项集合中决定一件产品(有关回顾参见Keane,2013)。此类研究通常一次关注一类产品,并对少数产品之间的选择建模。研究重点往往是估计交叉价格弹性,从而可以分析企业合并和价格调整之类的反事实情形。虽然把个体偏好纳入可观测特征是普遍的做法,但此类模型中隐藏变量的数量通常较少。标准的模型设定首先是关于消费者i在时间t对产品j的效用:
 |
从机器学习的角度看,反映消费者选择的面板数据可以利用上述矩阵填充法来分析。模型会利用不同消费者有相似购买模式的产品以及对不同产品有相似购买模式的消费者来做推断。不过,此类模型通常不太适合分析两个产品相互替代的程度,以及分析反事实情形。
例如,雅各布斯(Jacobs et al.,2014)建议,在有大量产品类型的在线购物场景下,用相关的隐藏因子分解方法来灵活模拟消费者的异质性。他们利用一家中等规模的在线零售商的数据,涉及3 226种产品,在类型和品牌层面加总之后,缩减为440种产品。该研究没有分析消费者对价格变化的反应以及类似产品之间的替代,而是秉承机器学习研究的精神,通过预测消费者将购买的新产品来评估模型的表现。
不同于这种把机器学习方法直接应用于产品选择的做法,近期的研究试图把机器学习方法同经济学中关于消费者选择的观点结合起来,主要是利用面板数据。此类研究文献的一个主题是,模型中如果考虑了某些问题的结构特性,其表现会优于不考虑结构性特征的其他模型。例如,经济学中的消费者选择模型采用的函数形式带有大量结构性特征,反映了一个类型中的产品如何相互作用。比如它们决定了某个产品的价格提高会引起对其他产品的选择发生特定变化。由于这些函数形式包含的约束条件很好地模拟了现实情况,它们就能极大地改进估计的效率。因此,把数十年经济学研究已经证明非常有效的函数形式纳入考虑,可以改进模型的表现。
当然,经济学模型通常没有包含面板数据可能反映的所有信息,而矩阵填充法往往能够对此类信息加以利用。另外,计算难题妨碍了经济学家探讨多种产品类型中的消费者选择,而在现实中,消费者对一类产品的购买数据包含着对其他类产品的购买信息,而且这些数据还能揭示哪些产品会有类似的购买模式。所以,此类新混合方法的研究文献采用的优秀模型经常利用了矩阵填充法开发的技术,特别是矩阵因子分解方法。
为说明矩阵因子分解如何改进标准的消费者选择模型,我们可以把消费者i在时间t对产品j的效用表述为:
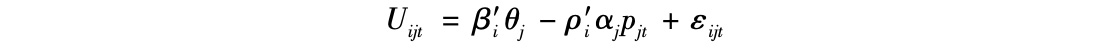 |
其中,βi,θj,ρi和αj是隐藏变量的向量。例如,向量θj可以理解为产品j的隐藏产品特征的向量,βi代表消费者i对这些特征的隐藏偏好。选择概率的基本函数形式不变,只是效用成了隐藏特征的函数。
此类模型直到最近才在机器学习文献中被采用,部分原因是选择概率的函数形式在大量隐藏参数上属于非线性,让计算变得极具挑战性。相比而言,传统的机器学习模型可以把所有产品都视作独立选择(如Gopalan et al.,2015),让计算变得简单许多。有研究(Ruiz et al.,2017)采用了机器学习中的高明计算技术,尤其是随机梯度下降和变分推断(variational inference),加上几个近似方法,使模型可以扩展到数千个消费者、每个消费者在数十到数百次购物中对数千个产品做选择的情形。该研究并未利用关于产品类型的任何数据,而是试图从产品属于替代品或互补品,并包含大量价格变化的数据中去学习。相反,阿西等人(Athey et al.,2017b)的研究纳入了关于产品类型的信息,并假设消费者在给定购物清单中对每个类型只购买一件产品。该研究还引入了嵌套逻辑结构(nested logit structure),使得效用与同一类型中的不同产品形成关联,以便更好地解释消费者是否选择购买某个类型的产品。
有的研究(Wan et al.,2017)则采用了与之密切相关的一种方法,利用包含价格差异的隐藏因子分解方法。该研究把消费者选择构建为一个三阶段过程:(a)选择是否购买某种产品类型;(b)在既定类型之中选择具体产品;(c)选择要购买的产品的数量。该研究利用了两个不同数据库的消费者忠诚度交易信息。在所有上述方法中,利用经济学的效用最大化方法,我们可以开展传统分析,如价格变化对消费者福利的影响等。对基于隐藏产品特征的研究,塞梅诺娃等人(Semenova et al.,2018)提出了一种补充方法,利用观测到的高维产品特性(如文字描述和图像),而非隐藏特征。
9.文本分析
有大量机器学习文献是针对文本数据的分析,对这个领域的充分阐述已超过了本文的范围。近期的研究综述可参见根茨科等人(Gentzkow et al.,2017)的研究。本节将提供一个高度概括的介绍。
首先我们设想有一个包含了N个文件的数据库,编号为i= 1,…,N,每个文件都包含一个词汇集合。表述该数据库的一种方式是采用N×T的矩阵,记为C,其中T是语言中使用的词汇数量,矩阵的每个元素则表示词汇t是否在文件i中出现。这种表述方式忽略了词汇在文本中的次序,会丢失信息。更丰富的表述方式是让T代表二元词串(bigram)的数量,二元词串则是在文件中彼此紧邻的一对词汇,或者三个或更多词汇组成的顺序连接。
对于此类数据,我们可以做两种类型的操作:一种是非监督学习,另一种是监督学习。对非监督学习的情形,目标是找到矩阵C的一个低秩表达式。由于如上文所述,低秩矩阵可以由因子结构矩阵来近似,这相当于找到文件的一组k个隐藏特征(标记为β)和对应的一组隐藏权重(标记为θ),使词汇t出现在文件i中的概率为函数θ′iβj。对问题的这种理解将它转化为一个矩阵填充问题,如果我们对C中的随机选择元素保留一个测试集,而模型能够很好地预测保留元素,则可以认为某个表达式的表现良好。上述矩阵填充的所有方法都可以在这种情形下得到应用。
这些理念的一种运用被称为主题模型(topic model,有关综述可参阅Blei and Lafferty,2009)。该模型是一种特定的数据生成模型,其中有若干主题,属于隐藏变量。每个主题都与词汇的分布有关,一篇文章的特征反映在每个主题的权重上。主题模型的目标是估计隐藏主题、每个主题的词汇分布以及每篇文章的权重。这方面的一种流行模型被称为隐藏的狄利克雷配置模型(latent Dirichlet allocation model)。
近期出现了更复杂的语言模型,虽然简单的机器学习模型运转不错,但把特定问题的结构纳入考虑往往能有所帮助,并可以采用在大众应用领域的高明机器学习方法。一般来说,这些被称为词汇嵌入方法(word embedding methods)。它们试图反映语言中隐藏的语义学结构。(*3.参见Mnih and Hinton(2007);Mnih and Teh(2012);Mikolov et al.(2013a,b,c);Mnih and Kavukcuoglu(2013);Levy and Goldberg(2014);Pennington et al.(2014); Vilnis and McCallum(2015);Arora et al.(2016);Barkan(2016); Bamler and Mandt(2017)。)我们来看神经概率语言模型(neural probabilistic language model)的例子,该模型设定了词汇序列的联合分布概率,利用词汇表的向量表述来实现参数化(Bengio et al.,2003,2006)。词汇的向量表述(被称为分布式表述)可以包含关于词汇的使用和意义的相关内容(Harris,1954;Firth,1957;Bengio et al.,2003;Mikolov et al.,2013b)。
另一类模型采用了监督学习方法,此类方法用于研究者希望从文本中了解到某些特征的情形。例如一篇评论的受欢迎程度、议员们讲话的政治极端程度、某家企业的推特内容的正面或负面属性等。此时,结果变量是包含了我们关注的特征的一个标签。一种简单的监督学习模型利用数据矩阵C,把每篇文件i视为一个观测单元,把矩阵C中的列(分别对应某个特定词汇是否出现在一个文件中)作为回归中的协变量。由于T通常远大于N,利用允许正则化的机器学习方法就显得非常重要。有时在应用某种监督学习方法(如非监督学习的主题模型)之前,还采用了其他类型的降维技术。
还有一种方法是借鉴生成模型。我们把文件中的词汇设想为结果向量,而且与主题模型类似,我们关注的文件特征决定了词汇的分布。这方面的例子之一是监督学习的主题模型,把训练数据库中观测到的特征信息纳入生成模型的估计。然后以被估计模型为基础,预测未标签文件的测试数据库的这些特征(更多细节参见Blei and Lafferty,2009)。

























 京公网安备 11010502034662号
京公网安备 11010502034662号 
{kind=link}
评论区 0
本篇文章暂无评论