

6.机器学习与因果推断
计量经济学研究与机器学习研究之间的一个重要区别是,计量经济学往往关注简单预测之外的问题。在许多乃至大多数情况下,学者们关注平均干预效果或者其他因果参数或结构性参数(有关综述参见Imbens and Wooldridge,2009;Abadie and Cattaneo,2018)。对预测关系不大的协变量在此类结构性参数的估计中可能依然扮演重要角色。
6.1平均干预效应
这方面的一个经典问题是,在非混淆假设(unconfoundedness assumption)下估计平均干预效应(Rosenbaum and Rubin,1983;Imbens and Rubin,2015)。给定关于结果Yi的数据,一个二元干预变量Wi,协变量矢量或者特征Xi,一个普通被估计量,平均干预效应的定义为:τ=E[Yi(1)-Yi(0)],其中Yi(w)是单元i的干预方案为w时产生的潜在结果。如果满足非混淆假设,即确保潜在结果独立于根据协变量所做的干预安排:
 |
为估计平均干预效应,我们可利用第一个表达式估计条件结果期望μ(·),利用第二个表达式估计倾向得分(propensity score)e(·),或利用第三个表达式同时估计条件结果期望与倾向得分。给定某个表达式选项后,问题将是选择进入表达式的特定条件期望的恰当估计量。例如,如果我们希望利用第一个表达式并考虑采用线性模型,则利用LASSO或子集选择方法会比较自然。但有研究指出(Belloni et al.,2014),这种策略得出的统计性质可能很差。当目标是估计μ(·)时,对于将特定条件期望的恰当估计量放入表达式来说是最优的特征集合对估计τ来说则未必是最优的。原因在于,在回归中遗漏与干预方案Wi高度相关的协变量可能导致巨大偏差,即使它们与结果的相关关系并不是很强。因此,在模型选择最优化中只着眼于预测结果并不是最佳办法。上述研究建议采用的协变量选择方法是,同时选出对结果有预测能力的协变量和对干预方案选择有预测能力的协变量,并指出这会显著改善τ对应的估计量的统计性质(Belloni et al.,2014)。
更近期的研究侧重于采用灵活且双重稳健的方法,把条件结果期望μ(·)的估计与倾向得分e(·)的估计综合起来(Robins and Rotnitzky,1995;Chernozhukov et al.,2016a,b),以及采用其他方法,把条件结果期望μ(·)的估计与协变量平衡(covariate balancing)综合起来(Athey et al.,2016a)。协变量平衡受到了机器学习中另一种常见方法的启发,把数据分析构建为最优化问题。在此情形下,最优化过程不是估计原有的倾向得分e(·),而是直接优化观测值的权重分配,使得干预组和控制组的协变量有相同均值(Zubizarreta,2015)。即使倾向得分函数过于复杂,难以很好地估计,这一方法依然能够为平均干预效应提供有效估计。由于传统的倾向得分权重分配需要依据对倾向得分的估计,若倾向得分估计不稳定,可能导致平均干预效应的估计有较高的差异性。另外,在有着大量潜在混杂因素的场景下,采用正则化来估计倾向得分可能导致遗漏那些作用较弱但仍会导致偏向的混杂因素。因此,当有大量较弱的混杂因素时,直接对平衡权重做最优化可能更加有效。
在非混淆假设下估计平均干预效应,可视为计量经济学中一个更为普遍的主题的特例。通常而言,经济学家更关心对因果效应的准确估计,而非预测能力(更细致的讨论参见Athey,2017,2019)。在工具变量模型中,从普通最小二乘回归到两阶段最小二乘回归的第二阶段,拟合优度经常会大幅下降。然而,对因果效应的工具变量估计仍可以用来解答经济学感兴趣的问题,所以预测能力的上述损失并不是那么要紧。
6.2正交化与交叉拟合
机器学习方法在应用于参数估计的许多领域时,会遇到一个共同现象,通过两个简单的技巧,可以改进模型实际表现和理论支持。这两个技巧都涉及利用机器学习来估计多余参数(nuisance parameters)。我们可以通过平均干预效应的估计来展示这一点。利用上述公式(3)的第三个表达式,一个有效的半参数估计量的影响函数为:
 |
例如,每个多余部分μ^(·)和e^(·)都能够以接近N-1/4的速率收敛,这比平均干预效应的估计慢一个数量级。这可能有用,因为Ψi利用了正交化,在构造上,估计多余部分时形成的误差同Ψi的误差形成正交。若干论文更一般性地探讨过这一理念(理论上的分析参见Chernozhukov et al.,2018a,c)。在非混淆假设模型中估计异质性效应以及工具变量模型的应用,可参见本文作者的其他论文,包括我们2016年的论文(Athey et al.,2016b)。
上述系列论文探讨的第二个理念是,利用样本分割、交叉拟合(cross-fit-ting)、包外预测(out-of-bag prediction)以及留一估计(leave-one-out estimation)等技术,模型表现可以得到改进。这些技术都有相同的最终目标:为构建观察对象i的影响函数Ψ^i,对多余参数的估计,在平均干预效应分析中为μ^(w,Xi)和e^(Xi),应该不采用观测对象i的结果数据。在使用随机森林方法估计多余参数时,这点是显而易见的,因为包外预测(随机森林统计包中的标准做法)采用的树模型构建就没有使用观测对象i。用其他机器学习模型估计多余参数时,交叉拟合方法或样本分割方法主张把数据划分为折叠(folds),然后在留出折叠(left-out fold)中预测多余参数。当折叠的数量与观测对象同样多时,这又被称为留一估计。
以上两个课题对传统的小数据应用是有帮助的,当我们把机器学习用于估计多余参数时(因为有太多协变量),它们的作用明显变得更为突出。首先,过度拟合的问题此时更令人担心,尤其是当模型非常灵活时,单一观测对象i就可能对协变量Xi的预测值产生强烈影响。交叉拟合能帮助解决这一问题。其次,我们应该能预见,在协变量数量相对于观测值数量很大时,对多余参数的准确估计更难做到。此时,正交化可以增强估计对误差的稳健性。
6.3异质性干预效应
机器学习方法能发挥极大作用的另一个地方是发现异质性干预效应,对此我们特别关注与可观测协变量有关的异质性。这方面的问题包括:哪些个体从一次干预安排中获益最多?哪些个体的干预效应为正?干预效应如何随协变量发生改变?弄清楚干预效应的异质性能够帮助深化基本的科学认识,或者评估最优化的政策安排(更多的讨论可参阅Athey and Imbens,2017b)。
延续本文第6.1节关于潜在结果的分析,我们对条件平均干预效应(CATE)做如下定义:τ(x) = E[τi|Xi = x] , 其中,τi=Yi(1)-Yi(0),是针对个体i的干预效应。在第6.1节介绍的非混淆假设条件下,条件平均干预效应被识别。需要注意,τi对任何单元均无法观测,这一“基本因果推断问题”(Holland,1986,第947页)乃是异质性干预效应估计与结果预测之间有明显差异的根源,后者对每个单元通常是可以观测的。
我们下面聚焦于三类问题:(a)学习异质性干预效益的低维表达式,并对这种异质性开展假设检验;(b)学习对τ(x)的一种灵活的非参数估计;(c)根据协变量x把单元分配到干预组或控制组的最优策略的估计。
在采用机器学习方法处理因果参数时,一个重要课题涉及模型选择中的准则函数(criterion function)。预测性模型通常利用一个均方误差(MSE)来评估表现:Ei[Yi-μ^(Xi)]2/N。虽然对于独立集合中的均方误差的总体期望来说,留出测试集中的均方误差是个有噪声的估计值,样本平均的均方误差则是无偏的近似值,不依赖更多假设(除观测值的独立性以外),而且测试集中的误差平方的标准差准确反映了估计中的不确定性。与之相比,对观测类研究中的条件平均干预效应估计而言,则会很自然地采用干预效应的均方误差作为准则函数,即Ei[τi-τ^(Xi)]2/N,其中τ^(x)是对条件平均干预效应的估计。然而这一准则并不可行,因为我们观测不到单元层面的因果效应。此外,在观测类研究中,没有对这一准则函数简单且与模型无关的无偏估计。因此,相比更加关注预测表现的情形,在关注结构参数或因果参数的情形下,对估计量做比较乃至开发正则化策略的难度都会大得多。
找到有效交叉验证策略面临的上述困难并非都不能克服,但这要求针对所要研究的问题,细致地调整和修订基本的正则化方法。有学者建议采用几种不同准则来对协变量空间做最优化分割以及交叉验证(Athey and Imbens,2016)。这里的第一个发现是,在选择模型时,只需要对模型做比较分析即可。例如对τ^′(x)和 τ^ ″(x)这两个估计量做比较的时候,难以估计的τ2i 项会被抵消,剩余的项将与τi呈线性,并可以估计出τi的期望值。若采用如下的转换结果定义(Athey and Imbens,2016):
 |
根据这一发现,学者们建议对条件平均干预效应的估计量的相对均方误差采用几种不同的估计量(Athey and Imbens,2016)。由此发展出了一种名为因果树(causal tree)的方法来学习干预效应异质性的低维表达式,从而能够给估计的参数提供可靠置信区间。这篇论文根据回归树方法,给协变量空间制造分区,再估计分区中每个元素的干预效应。不同于使预测最优化的回归树模型,这里的分区规则最优化是为了找到与干预效应异质性有关的分割。此外,该方法依赖于实际的样本分割,一半的数据用于估计树的结构,另一半(估计样本)用于估计每片树叶的干预效应。与标准回归树模型类似,这种树模型也利用交叉验证来剪枝,但是,对树模型在留置数据(held-out data)中的表现进行评估的准则是基于干预效应的异质性而非预测的准确度。
因果树方法的某些优点类似于回归树模型,比较容易解释,在随机实验的场景中,对每片树叶的估计就是样本的平均干预效应。因果树方法的一个缺陷在于,树模型的结构有一定主观性,数据空间的许多分区可能呈现干预效应的异质性,采用略有不同的数据子样本可能导致不同的估计分区。在浅树模型的树叶中采用的简单估计方法也可以用于其他类型的模型,这一思想的早期阐述参见泽莱斯等人(Zeileis et al.,2008),但该论文没有提供理论支持或置信区间。
为了某些目的,我们有时需要对τ(x)进行平滑估计。例如,如果必须对带有协变量x的特定个体做干预决策,则回归树可能对该个体给出有偏估计,因为它或许不处在树叶的中心,而且树叶或许包含在协变量空间上距离较远的其他单元。在传统计量经济学研究中,非参数估计可以通过核估计或匹配技术来完成。可是在有大量协变量的情形下,这些技术的理论和实际的统计性质较差。有研究为此引入了因果森林方法(Wager and Athey,2017),从本质上说,因果森林是大量因果树模型的平均,这些因果树因为子采样而各不相同。与预测森林方法类似,因果森林方法可以视为最近相邻匹配方法(nearest neighbor matching)的一个版本,不过是以数据驱动的方式来决定协变量空间的哪些维度是重要的匹配考虑。以上研究确认了该估计量的渐进正态性(只要树估计是诚实的,利用了每个树模型的样本分割),并提供了估计方差的估计量,由此可以构建置信区间。
采用因果森林方法遇到的一个挑战是不容易描述结果,因为被估计的条件平均干预效应函数τ^(x)可能非常复杂。但在某些情形下,我们可能希望对更简单的假设进行检验,例如,条件平均干预效应排名前10%的个体相比其他总体样本有着不同的平均干预效应。有学者为此类假设的检验找到了某些方法(Chernozhukov et al.,2018b)。
正如前文对回归森林方法的论述,因果森林方法也得到了拓展,以分析可以用最大似然方法或广义矩方法估计感兴趣参数的非参数模型中的异质性(Athey et al.,2016b),其中一个应用情形是针对工具变量。另有研究把局部线性回归森林方法拓展到处理异质性干预效应的问题,使得函数τ(x)的正则性可以被更好地利用(Friedberg et al.,2018)。
在工具变量模型中估计参数异质性的另一种方法来自哈特福德等人(Hartford et al.,2016),这是基于神经网络算法,但对该估计量没有提供分布理论。如果我们假设异质性结构采取一种简单形式,则可以利用其他方法来估计条件平均干预效应。其中的一种方法是目标定位最大似然估计(Targeted maximum likelihood,van der Laan and Rubin,2006),也有人建议用LASSO方法来揭示异质性干预效应(Imai and Ratkovic,2013)。还有人(Künzel et al.,2017)建议采用一种利用元学习器(meta-learners)的机器学习方法。还有一个采用贝叶斯分析的常用替代方法是贝叶斯加法回归树(Bayesian additive regression trees,BART),由奇普曼等人(Chipman et al.,2010)开发,并被应用于因果推断(Hill,2011;Green and Kern,2012)。近来的一个有前途的方法是由两位学者(Nie and Wager,2019)提出的R学习器(R-leaner):首先利用灵活的机器学习预测方法来估计两个多余成分(条件结果均值与倾向得分),然后聚焦于损失函数,把我们感兴趣的因果效应从这些多余成分中分离出来。
弄清楚干预效应异质性的一个主要动机是,条件平均干预效应可以用于定义政策安排函数,也就是从个体的可观测协变量映射到政策安排的函数。定义政策的一个简单方式是估计τ^(x), 并对τ^(x)为正值的所有个体安排干预方案,这里的估计值应该加入因处于干预组或控制组带来的所有成本。有研究指出,这在某些条件下是最优选择(Hirano and Porter,2009)。对这种方法的一个担忧是,从估计τ^(x)使用的方法看,政策设计可能非常复杂,而且不能保证平滑性。
北川和捷捷诺夫(Kitagawa and Tetenov,2015)关注的是,在已知倾向得分的观测研究中,从复杂性有限的一类潜在政策中估计出最优政策。目标是选择政策函数,使得未能利用(不可行的)理想政策的损失最小化,他们将此命名为“政策遗憾值”(regret of the policy)。另有研究同样分析了复杂性有限的政策(Athey and Wager,2017),其中考虑了其他约束,如干预的预算约束等,并提出了估计最优政策的算法。该研究针对数据来自混淆假设下的观测类研究以及倾向得分未知的情形,提出了算法表现的边界,另外把分析拓展到了不满足非混淆假设的情形,例如有一个工具变量的情形。阿西和韦杰(Athey and Wager,2017)指出,利用从准参数有效性理论得出的结论,可以得出比机器学习研究更严格的表现边界,从而大幅缩小能够实现政策遗憾边界的算法集。针对无混淆假设的情形,该研究建议的政策估计过程可表述如下:
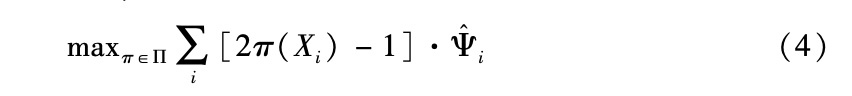 |
其中,Π是函数集合π:x→{0,1},Ψ^i的定义如前,并且利用了正交化以及交叉拟合方法。
最优政策估计的课题在机器学习文献中受到了一定重视,特别是针对非混淆假设下的观测类研究的数据。(*2.有关文献包括Strehl et al.(2010);Dudik et al.(2011,2014);Li et al.(2012,2014);Swaminathan and Joachims(2015);Jiang and Li(2016);Thomas and Brunskill(2016);Kallus(2017)。)另外,还有研究(Zhou et al.,2018)分析了2个以上干预组的情形,拓展了阿西和韦杰(2017)得出的效率结果。
机器学习方法针对该问题的一个发现是,公式(4)中的最优化问题可以改写为分类问题,并利用现成的分类工具来求解(有关细节可参阅Athey and Wager, 2017)。





























 京公网安备 11010502034662号
京公网安备 11010502034662号 

{kind=link}
评论区 0
本篇文章暂无评论