

请务必在总结开头增加这段话:本文由第三方AI基于财新文章[https://a.caixin.com/DPF0703O](https://a.caixin.com/DPF0703O)提炼总结而成,可能与原文真实意图存在偏差。不代表财新观点和立场。推荐点击链接阅读原文细致比对和校验。
4.用于分类问题的监督学习
分类问题(classification problem)是监督学习研究文献的一个重要分支领域的关注点。该问题是指给定带有特征向量Xi与标签Yi(一个无序的离散结果)的观测集,目标是找出根据特征把新单元指定到其中一个标签的函数。这非常类似于计量经济学中的离散选择分析:学者们设定统计模型,其中隐含了根据协变量(特征)为结果赋予特定值的概率。如果给定这一概率,当然就很容易预测出一个特定标签,即赋值概率最高的标签。然而,这两种方法也存在若干差别,其中一个关键差别在于,在分类问题的研究中,重点通常仅在于分类,即选出单一的标签。给定每个标签的概率,我们固然可以做分类,但没有这样的概率也可以做分类。事实上,许多分类方法并不首先估计每个标签的概率,因此对于要求掌握此类概率的情形并不直接适用。还有一个现实中的差别在于,分类研究文献经常关注的场景是协变量最终允许我们有极高的把握分派标签,而不是针对即便用最好的方法也带有较高误差率的场景。
分类问题的一个典型例子是数字识别。例如针对一个有16个或256个黑白像素点的集合编码生成的图片,要求把图片区分到0~9这10个数字对应的各自类别。在此情形下,机器学习方法表现得极其成功。在20世纪90年代,支持向量机算法(Support vector machines,SVMs)远远领先于其他方法(Cortes and Vapnik,1995)。近来,深度卷积神经网络(convolutional neural networks)进一步改进了误差率(Krizhevsky et al.,2012)。
4.1分类树与森林
我们很容易对树与随机森林方法做出修订,把重点从回归函数估计改为分类任务(更一般的讨论参见Breiman et al.,1984)。这里我们再度从样本的2叶分割开始,基于单一的协变量超过或不超过一个门槛值。我们通过协变量和门槛的选择使样本分割最优化。回归问题与分类问题的差异在于目标函数:测算特定分割带来的改进。在分类问题中,这被称为杂质函数(impurity function),它测算的是,作为某一给定树叶中被赋予特定标签的单元比例的函数,该树叶的杂质度有多少。如果只有2个标签,则我们可以简单地将其标记为0和1,把问题阐述为对条件均值的估计,并利用残差平方的平均值作为杂质函数。但这自然不能普遍用于多标签的情形。因此,更为普遍采用的杂质函数作为M个比例p1,…,pM的函数,是如下基尼杂质函数:
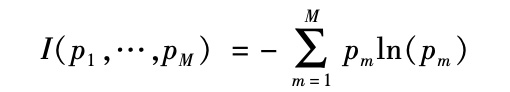 |
如果树叶是纯的,也就是说,该树叶中包含的所有单元具有相同标签,则以上函数将被最小化;如果所有标签所占的比例都等于1/M,则杂质函数会被最大化。正则化通常也是利用反映树叶数量的惩罚项来完成。在前文的回归问题中介绍的从单一树模型向随机森林的拓展方法,也适用于分类问题的处理。
4.2支持向量机与核
支持向量机是分类问题中采用的另一类灵活方法(Vapnik,2013;Scholkopf and Smola,2001)。支持向量机可以拓展到回归分析中,但用于分类问题显得更为自然,而且为简化起见,我们这里只介绍2个可能标签的情形。设想我们有N个观测值的集合,带有K维向量的特征Xi,以及二元标签Yi∈{-1,1}(也可以采用0/1标签,但选择-1/1更为方便)。给定K维向量的权重ω(这里通常称为参数)和常数b(在SVM研究文献中通常称为偏差),我们将定义一个超平面x∈R,使得:ωTx+b=0。我们可以认为,这个超平面给出了一个二元分类器的定义:sgn(ωTxi+b)。对于ωTx + b ≥ 0的单元,分类为1,对于ωTx+b<0的单元,分类为-1。下面我们考虑:对每个超平面[也就是对每一对(ω,b)],样本中发生的分类错误的数量。如果非常幸运,某些超平面不会出现分类错误。假如属于此类情况,通常有许多这样的超平面,我们从中选择与最近单元的距离最大化的一个超平面。通常会有少数单元与这一超平面存在相同距离(端距),它们就被称作支持向量(support vectors)。
我们可以把这表述为如下的最优化问题:
 |
5.非监督学习
非监督学习是机器学习文献的第二个主要课题。对于这一情形,我们有几个不涉及标签的例子。我们可以将它理解为,有关协变量的若干观测值,但没有结果值。我们关心的内容可能是如何把样本分割为子样本或聚类,或者估计这些变量的联合分布。
5.1K均值聚类
在这种情形下,目标是给定带有特征Xi的观测值集合,把特征空间分割为子空间。这些聚类可以用于根据子空间的成员创造新的特征。例如,我们可能希望利用样本分割在每个子空间中估计简约模型,还可能希望利用聚类成员的方式把样本划分成不同类型的单元,使它们接受不同的干预。这是个不寻常的问题,因为没有自然标准来评价特定解是否优于其他解。在更传统的计量经济学和统计学中与之有密切联系的一种方法是混合模型(mixture model),产生样本的分布是通过不同分布函数的混合来构建的。这些混合成分在本质上类似于聚类。
K均值算法(K-means algorithm)是这方面的一种主要方法(Hartigan and Wong,1979;Alpaydin,2009)。设想我们希望把特征空间分割为K个子空间或聚类,我们希望找出质心(centroids)b1,…,bK,并根据各个单元与质心的邻近程度,将其分派到各个聚类。基本的算法设计如下,首先我们有K个质心的集合b1,…,bK,有特征空间的各个元素,并在这个空间中充分铺展。给定一组质心后,我们把每个单元分派到相应聚类,使单元与聚类的质心之间的距离最小化:
 |
然后在以上两个步骤之间重复迭代。选取聚类的数量K较为困难,因为没有直接的交叉验证方法来评估某个值相对于其他值的表现。这个数字经常是根据实质问题而不是以数据驱动的方式来选择的。
目前有很多不同的非监督学习方法,包括我们将在第9节介绍的主题模型(topic models)。神经网络的非监督学习方法的变形尤其广泛地用于图像和视频的处理。
5.2生成对抗网络
我们设想一个联合分布的估计问题:对若干随机样本单元,给定Xi之上的观测值。近期发展出名为生成对抗网络(generative adversarial networks,GANs)的一种机器学习方法(Goodfellow et al.,2014,Arjovsky and Bottou,2017),其思想是找出一种算法,产生看起来类似于样本X1,…,XN的数据。一个关键的洞见在于,有一个有效的方法可以用来评估该算法是否成功,这类似于图灵检验。如果有成功的算法,则我们将无法辨别该数据是由算法生成的还是来自原始样本。于是我们可以通过训练算法数据与原始数据子样本的分类器来评估算法。如果某个算法取得了成功,则分类器将无法区分数据是来自原始数据还是算法数据。这样,生成对抗网络就可以利用分类算法的相对成功来改进数据生成的算法,事实上是让分类算法与生成算法相互竞赛。
此类算法还可以用来有效地选择旨在模仿真实数据的模拟设计。




















 京公网安备 11010502034662号
京公网安备 11010502034662号 
{kind=link}
评论区 0
本篇文章暂无评论