
*Susan Athey, 斯坦福大学技术经济学教授、美国经济学会会长、斯坦福大学Golub Capital Social Impact Lab创始主任,2007年克拉克奖得主,主要研究领域:产业组织、微观经济学理论、应用计量经济学、基于拍卖的市场设计、网络经济学,主要关注在线广告和新闻媒体经济学、不完全信息的动态机制设计和博弈,分析拍卖模型的计量经济学方法。Guido W.Imbens,斯坦福大学应用计量经济学教授、经济学教授,2021年诺贝尔经济学奖得主,因本斯从事计量经济学和统计学研究,研究重点为:开发在观察性研究中得出因果推论的方法,以及对匹配方法、工具变量和回归断点设计的利用。原文“Machine Learning Methods That Economists Should Know About”发表于 The Annual Review of Economics(2019),vol.11,第685—725页。
1.引言
伯克利加州大学的统计学家布雷曼在2001年的《统计科学》(Statistical Science)上发表了一篇颇有挑衅性的论文(Leo Breiman,2001b,第199页),谈及统计学中以模型为基础的方法和以算法为基础的方法的区别:
利用统计建模从数据中得出结论,这里有两种文化:一种假设数据从给定的随机模型中产生;另一种则利用算法模型,把数据机制作为未知来考虑。
布雷曼接着指出:
过去,统计学界基本上只使用数据模型,这种偏执导致了无效的理论和受质疑的结论,并让统计学家们难以处理各种有趣的现实问题。而算法模型从理论和实践看都在统计学领域之外获得了飞速发展,既能用于复杂的大数据库,也能给较小的数据库提供不同于数据模型的更为精确和有效的分析工具。如果统计学界把利用数据解决问题作为自己的目标,那我们就应该超越对数据模型的单纯依赖,接受更加丰富多样的研究工具。
布雷曼当时的总结已不再适用于如今的统计学界。这个领域已广泛接受了机器学习(machine learning,ML)的革命方法,即他所说的算法模型文化,并且许多教科书把机器学习方法同更加传统的统计学方法放在一起讨论(如Hastie et al.,2009;Efron and Hastie,2016)。虽然这些方法在经济学中的应用要慢一些,但如今也开始在实证分析中广泛出现,成为快速增加的方法论研究文献的主题之一。我们希望在这篇评论文章中指出,正如布雷曼对统计学界的评论那样,经济学家和计量经济学家也“应该超越对数据模型的单纯依赖,接受更加丰富多样的研究工具”。我们将介绍对实证研究者有用的某些工具,并认为这些工具应该成为计量经济学标准研究生课程的组成部分,因为我们赞同布雷曼的看法“把利用数据解决问题作为自己的目标”,同时我们认为计量经济学的本质就是在不确定情况下的决策(如Chamberlain,2000),而且希望学生们能够同经常采用算法模型等方法的其他领域的学者有效开展交流。机器学习研究文献中发展出来的方法具有普遍适用价值,尤其擅长处理大数据的情形:我们在大量单元上观测到信息,或者每个单元上包含许多条信息,而且经常超出单一横截面数据的简单情形。对于此类情形,机器学习正在成为各类学科共同采用的标准研究方法。因此,经济学家的工具库在保留传统应用计量方法的优势之外,也需要相应地与时俱进。
相比更广泛的统计学界,经济学领域对机器学习方法的采用为什么慢很多?很大一部分原因或许来自布雷曼所说的文化。经济学期刊看重的研究方法带有某些规范特性,是许多机器学习方法本身不能提供的,包括估计量和检验的大样本特征,如一致性、正态性和有效性等。与之相比,机器学习类文献的关注点往往是算法在特定场景下的实用特性,其规范结果属于另一种类型,例如对误差率的保证等。对计量经济学论文传统上报告的那类理论结果,机器学习文献通常较少涉及,当然近期有了某些重要突破(Wager and Athey,2017,Farrell et al.,2018)。目前没有规范的研究结论表明,对于监督学习(supervised learning)问题,深度学习或神经网络方法普遍优于回归树(regression trees)或随机森林方法(random forests)。而且至少从短期看,这方面的比较不太可能得出一般性结论。
在许多情形下,构建有效的大样本置信区间的能力是重要的,但我们不应该轻易排除无法(或暂时无法)提供此类结果却具有其他优势的分析方法。这些方法在特定数据库中展示的超越其他方法的样本外预测能力在实践中极具价值,然而在计量经济学中还很少被列为目标或受到重视。有学者指出,某些实质性问题被很自然地归入预测问题,就此类情形的研究目的而言,评估测试组的拟合效果往往已经足够(Mullainathan and Spiess,2017)。而在其他一些情形下,一个预测问题的结果是对主要分析对象的一个输入,不需要对超出收敛速率的预测成分做统计分析。可是还有许多情形,我们有必要为感兴趣的参数提供有效置信区间,例如对于平均干预效应(average treatment effect)。此时,标准差或置信区间反映的不确定程度可能成为是否实施干预决策的重要参考内容。因此我们认为,随着机器学习工具在未来被更加广泛地采用,学者们需要明确阐述自己的研究目标,以及自己采用的算法或估计量的某些特性为什么是重要的。
本文的一个主题是,虽然在某些情形下简单地从机器学习研究文献中借鉴算法可以取得效果(参见Mullainathan and Spiess,2017),但在其他许多时候未必能适用。机器学习技术通常要求细致的调适,才能有效处理经济学家感兴趣的特定问题。或许最重要的调适类型是探讨问题的结构,例如许多估计对象的因果关系性质、变量的内生性、数据的构造(如面板数据)、在可替代产品集合中做离散选择的性质,以及经济学理论施加的可信约束(例如需求在价格上表现出来的单调性)或其他形状约束等(Matzkin,1994,2007)。统计学和计量经济学在传统上非常强调这些结构特征,并发展出了许多可加以利用的思想,而机器学习方法对此往往不重视。从实质内容和统计方法上利用好这些思想,将能够极大地改善机器学习的效果,这跟图像识别等特定问题中采用的机器学习的精心调适手段是相似的。还有一类调适是改变机器学习算法的最优化标准,把因果推断放到优先考虑中,例如控制混杂因子,或者发现治疗效果的异质性等。最后,我们可以采用样本分割方法(如Athey and Imbens,2016,Wager and Athey,2017),利用不同数据选择模型而非估计参数,或者采用正交化方法(如Chernozhukov et al.,2016a)等技术改善机器学习的估计量的表现,这在某些情形下可以带来估计量的渐进式正态性等理想特征(如Athey et al.,2016b;Farrell et al.,2018)。
本文将介绍一系列工具,我们认为它们应该成为实证经济学家工具库的组成部分,并纳入计量经济学研究生课程。这当然来自主观选择,而且鉴于此类研究文献的发展速度,相应工具清单会快速变化。另外,我们对相关议题的讨论并不很完备,只是着眼于对传递重要思想和见地的相关方法的简介,并提及更全面的其他参考资料。排在我们清单上第一位的是非参数回归,在机器学习研究文献中的术语则是用监督学习解决回归问题。排在第二位的是介绍用于分类问题的监督学习,与离散反应模型中的非参数回归密切相关,但不完全相同,可以说这是机器学习方法取得最大成功的领域。排在第三位的是非监督学习(unsupervised learning),或者说聚类分析和密度估计。排在第四位的是对异质性干预效应的估计,以及从个体观测特征对应于干预方案的最优政策选择。排在第五位的是实验设计中的机器学习方法,目前老虎机方法正在带来革命性影响,特别是在网络场景中。排在第六位的是矩阵填充问题,包括在因果面板数据模型和消费者离散产品集合选择问题中的应用。最后我们还将讨论文本数据分析。
我们注意到,近期还有几篇为经济学家而写的关于机器学习方法的文献综述,普遍涉及比本文内容更多的实证案例和应用参考。例如,范里安(Varian,2014)对若干重要的机器学习方法做了高水平的讨论。穆莱纳森和施皮斯(Mullainathan and Spiess,2017)重点分析了监督学习方法用于回归分析的好处,以及经济学领域中适用预测方法的各种问题。阿西等人(Athey,2017;Athey et al.,2017c)提供了广泛的研究视角,并重点介绍了近期采用机器学习方法开展因果分析的进展及其对经济学研究的普遍意义。根茨科等人(Gentzkow et al.,2017)出色地介绍了近期采用的文本分析方法,并侧重于在经济学中的应用。另外在计算机科学与统计学研究文献中还有几本优秀的教科书,适合不同层次的社会科学背景的研究者参考,其中包括黑斯蒂等人(Efron and Hastie,2016;Hastie et al.,2009)从统计学角度提供了较为全面的参考,布尔科夫(Burkov,2019)有非常易读的入门介绍,以及阿尔佩丁(Alpaydin,2009)和诺克斯(Knox,2018)的著作。当然这些著作都更多地采用了计算机科学的视角。
2.计量经济学与机器学习方法:目标、方法、场景
在本节中,我们将介绍本文的若干一般主题:传统计量经济学与机器学习研究在目标和关注点上有何差异?这些目标和关注点会如何影响对特定研究方法的选择?
2.1目标
传统的计量经济学方法是确定一个对象,即一个被估计对象,与数据的联合分布构成函数关系,若干杰出文献都提到过这一点(如Greene,2000;Angrist and Pischke,2008;Wooldridge,2010)。这个研究对象往往是统计模型的一个参数,模型则是描述一组变量(通常又取决于其他某些变量)在一组参数值(可以属于有限或无限集合)之下的分布。给定总体对象的一个随机抽样,对感兴趣参数和多余参数的估计是利用误差平方和等目标函数或似然函数,找出能够最好地拟合全体样本的参数值。这里的重点是目标估计量的质量,在传统上通过大样本效率来测算。学者们经常还会注重构建置信区间,报告点估计值和标准差。
与之相比,机器学习研究文献的重点往往是开发算法,例如一篇被广泛引用的论文《数据挖掘的10种顶级算法》(Top 10 Algorithms in Data Mining,Wu et al.,2008)。算法的目标通常是在已知其他变量的情况下预测某些变量,或者基于有限信息对单元分类,例如根据像素值识别手写数字。
用一个很简单的例子来说:我们要根据一个矢量值回归量或者特征Xi,构建某个结果为Yi的条件分布模型,假设我们确信:
 |
相应的问题是,如何针对上述损失函数,得出有良好性质的估计量(α^,β^)。它未必是最小二乘估计量。事实上,当特征维度超过2时,决策理论告诉我们,可以在期望误差平方上取得比最小二乘估计量更好的结果。后者不能被接受,也就是说有其他估计量胜过最小二乘估计量。
2.2相关术语
引发困惑的一个根源是,机器学习中采用了新的术语来指代原有研究文献中已经熟悉的概念。在回归模型中,用于估计参数值的样本经常被称作训练样本(training sample)。这些模型不是用于估计,而是用来训练。回归量、协变量或预测变量都被称为特征(features)。回归参数有时被称为权数(weights)。预测问题被区分为监督学习问题(能够同时观测到预测变量Xi与结果Yi)以及非监督学习问题(只能观测到Xi,然后将其纳入聚类,或者估计其联合分布)。无序离散响应问题通常被称为分类问题。
2.3验证与交叉验证
大多数计量经济学教科书在讨论线性回归问题时很少关注模型验证(validation)。回归模型的形式(无论是参数或非参数模型)与回归量集合都被视为外生给定,例如来自经济学理论的设定。在此情况下,研究者的任务是估计模型里的未知参数,更多关心的是有效完成这一估计步骤,往往通过定义大样本效率来实现。如果涉及模型选择的讨论,通常是以无效假设的检验来确认特定模型的有效性,其隐含设定是:应该能够找到一个真实模型,并用于完成后续任务。
例如上节提到的回归案例,假设我们希望预测一个新单元的结果,它随机地来自与我们的抽样样本相同的总体。我们可以不估计有一个截距和一个标量Xi的线性模型,而是选择估计仅有一个截距的模型。显然,如果β= 0,则该模型可以得出更好的预测结果。出于同样的理由,如果β的真实值接近于0(但并不完全等于0),则我们在回归中不考虑Xi,仍然可以得到更好的结果。样本外交叉验证(cross-validation)可以帮助做出此类决策。问题解决中涉及的两个部分对这种能力很关键。首先是把预测能力作为目标,而非着眼于特定结构参数或因果参数的估计;其次,该方法采用了样本外比较作为标准,而非样本内的拟合优度指标,这样可以确保获得对拟合的无偏比较。
2.4过度拟合、正则化与参数调整
相比标准的统计学和计量经济学文献,机器学习研究文献对过度拟合(over fitting)的关注要强得多。研究者们试图挑选能很好拟合的灵活模型,但不会以损害样本外预测的结果为代价。他们不太强调特定方法在大样本中具有渐进式优势的规范结果,而是针对特定数据库对不同方法加以比较,看哪种方法表现更好。这里的一个关键概念是正则化(regularization)。有学者指出,正则化理论是存在智能推断的首批信号之一(Vapnik,2013,第 9页)。
设想有很大一类复杂度各不相同的模型,例如以模型中未知参数的数量或者以反映模型能力或复杂度的万普尼克-契尔沃年基斯维度(Vapnik-Chervonenkis dimension)(*1.由俄罗斯统计学家、数学家弗拉基米尔·万普尼克(Vladimir Naumovich Vapnik)和阿列克谢·契尔沃年基斯(Alexey Chervonenkis)创建的统计学习理论(Statistical Learning Theory)。)来测算。此时不是直接对目标函数做最优化,例如在最小二乘回归中最小化残差的平方和,或者在似然函数中最大化对数值,而是在目标函数中加入一个项,以惩罚模型的复杂度。这种做法在传统计量经济学和统计学文献中有先例可循。一种是在似然情形下,学者们有时会给似然函数对数值加入一个项,该项等于样本规模的对数值乘以自由参数的数量除以2的负值,得到贝叶斯信息准则(Bayesian information criterion),或者该项等于自由参数的数量,得到赤池信息准则(Akaike information criterion)。在回归模型的贝叶斯分析中,另一种有很长历史的正则化估计方法是利用回归参数的先验分布(以0为中心,有独立于其他参数的常数先验方差)。而现代采用的正则化方法的不同之处在于,它们更多是由数据驱动的,正则化的数量明确地由样本外预测的表现决定,而不是依靠主观选择的一个先验概率分布。
 |
唯一的区别在于惩罚参数(penalty parameter)λ的选择方式。在规范贝叶斯方法中,这反映着参数的主观先验分布,因而是在事前做选择。而在机器学习方法中,λ的选择是通过样本外交叉验证,以实现样本外预测表现的最优化。它其实更加接近于实证贝叶斯方法,利用数据估计先验分布(如Morris,1983)。
2.5稀疏性
在机器学习文献的许多情形下,特征的数量很大,包括绝对数量很大以及相对于样本中的单元数量而言很大。然而,人们经常认为许多特征即使不完全无关,其重要性也较弱。这里的问题在于,我们或许事前不知道哪些特征重要,哪些可以从分析中排除而不至于显著影响预测能力。
黑斯蒂等人(2009,2015)这样阐述所谓的稀疏性原则(sparsity principle):
假设基本的真实信号较为稀疏,我们利用惩罚函数l1来试图修补。如果假设正确,我们在恢复真实信号上能做得不错……但如果假设错误,也就是说,实际情形在选定基础上并不稀疏,则惩罚函数l1不能很好地发挥作用。然而在此情形下,相对于贝叶斯误差来说,没有任何方法能做得很好。(Hastie et al.,2015,第24页)
确切的稀疏性事实上或许没有必要,在许多情形下采用近似稀疏性已经足够,即大多数解释变量的解释力非常有限(即使不为0),只有少数特征具有重要性(Belloni et al.,2014)。
在传统的社会科学实证研究中,学者们人为限制了解释变量的数量,而非通过以数据为根据的方式进行选择。让数据在变量选择程序中发挥更大作用似乎是一种明显的改进,尽管这个基本过程至少属于近似稀疏性的假设仍然非常强,而且以数据为根据的模型选择中的推断可能极具挑战。
2.6计算问题与可扩展性
相比传统的统计学和计量经济学研究,机器学习文献更加关注计算问题(computational issues),以及在大数据库中应用估计方法的能力。从统计效率的角度看或许有理论上的引人特性,但不适合匹配大数据库的解经常会被放弃,而更多地选择能够轻松适用超大数据库的方法,例如在线性回归的讨论中,关于最小绝对收缩和选择算子(LASSO)以及子集选择方法的优缺点比较。在分析中可能纳入大量特征的情形下,子集选择方法关注回归量子集的选择,再通过最小二乘法估计回归函数的参数。而LASSO方法具有计算方面的优势,比如,可以加入与参数的绝对值之和成比例的一个惩罚项。LASSO方法的一个主要优势在于,能找到有效办法计算出带有数百万个回归量的估计值。相比之下,最优子集选择回归是一个NP难题。到最近之前,人们认为回归量的数量只有在30多个以内时才可行,当然目前有研究认为或许可以拓展到1 000多个(Bertsimas et al.,2016)。由此也重新开启了在LASSO方法与最优子集选择方法都可行的场景下,两者之间孰优孰劣这一悬而未决的争论(Hastie et al.,2017)。有些迹象表明在信号-噪声比例低的情形下(符合社会科学的许多应用场景),LASSO方法可能有更好的表现,当然许多问题仍没有定论。在社会科学的许多应用场景下,问题的规模使得最优子集选择方法同样适用,而且与实质性问题相比,计算问题或许不是特别关键。
 |
在10次迭代后,我们可以重新调整数据库,做重复操作。如果学习速度ηk以合适的速率下降,则在相对温和的假设下,当目标函数为凸或伪凸时,随机梯度下降方法几乎肯定会收敛到全局最小值,在目标函数的其他情形下也几乎肯定会收敛到局部最小值。这一方法的概述和实际操作技巧可参阅博托(Bottou,2012)。
当▽Qi(θ)本身是期望值时,以上理念可进一步推广。我们可以考虑用蒙特卡洛积分来估值▽Qi。但我们不用通过很多蒙特卡洛模拟来得到积分的准确近似,而可以采用少数几次甚至一次模拟来实现。这一近似方法在经济学研究中的应用可以参见鲁伊兹等人(Ruiz et al.,2017;Hartford et al.,2016)。
2.7集成方法与模型平均
机器学习文献的另一个关键特征是利用集成方法(ensemble methods)和模型平均(model averaging)方法(如Dietterich,2000)。在许多情形下,单一模型或算法的表现不如把大量模型综合起来,并利用从最优化样本外表现中获得的权数(也称票数)来平均。一个令人叫绝的例子来自网飞大奖赛(Netflix Prize competition,Bennett and Lanning,2007),所有领先的参赛者都采用了模型综合方法,经常是利用大量模型的平均值(Bell and Koren,2007)。传统计量经济学研究中有两个与之有关的思想。显然,贝叶斯分析隐含着参数的事后分布的平均值。另外在采用混合模型时,也是把不同参数值混合起来用于单一预测。当然这两种情形下的模型都是对类似模型的平均,通常有着相同的设定,只是在参数值上有区别。而在现代研究文献以及网飞大奖赛的顶级入围者中,用于平均的模型可能大不相同,并且权重来自样本外预测能力的最优化而非对样本内拟合。
 |
我们还可以根据不同模型的预测变量在测试样本中的回归结果来估计权重,而不用要求权重的总和为1以及为非负值,因为随机森林、神经网络和LASSO等方法在处理无关特征、非线性和相互作用方面各有显著的优缺点。所以,对这些模型的平均可能带来严格优于单一模型的样本外预测结果。
针对面板数据的情形(Athey et al.,2019),我们可以采用集成方法,把不同的综合控制与矩阵填充法结合起来,找出超越单一方法表现的综合办法。
2.8推断
机器学习研究文献高度重视样本外表现,以之作为关键标准。但这损害了统计学与计量经济学在传统上关注的一个方面,即所谓推断(inference)能力,即至少在大样本中构建有效置信区间的能力。有学者指出(Efron and Hastie,2016,第209页):
或许是由于不受模型的约束,在算法的发展中,预测远远领先于推断论证。
虽然近期以来对特定场景下低维函数的推断方法取得了显著进步[如Wager and Athey(2017)关于随机森林的分析;Farrell et al.(2018)关于神经网络的分析],但对许多方法而言,目前仍不可能构建有效的置信区间,哪怕只是渐进式的。一个疑问在于,构建置信区间的能力是否像传统计量经济学认为的那样重要。对很多决策问题来说,预测可能是最关键的,推断至多属于第二重要。即使在可以做统计推断的场合,我们仍需注意,推断能力的保证往往需要牺牲预测效果。我们从传统的核回归方法(kernel regression)中能看到这种取舍,最优化期望误差平方的带宽(bandwidth)需要在偏差的平方与方差之间做权衡,这使得最优估计量有一个渐进式偏差,因而无法采用标准置信区间。解决办法可以是使用一个比最优水平更小的带宽,以消除渐进式偏差,但这显然要以增大方差作为代价。
3.针对回归问题的监督学习方法
机器学习与计量经济学文献都涉及的一个典型问题是,在给定一组协变量或特征之后,估算一个标量结果的条件均值。若以Yi代表单元i的结果,Xi代表协变量或特征变量有K个成分的矢量。则条件预期值为:
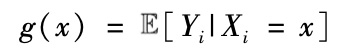 |
与传统的计量经济学教科书相比(如Greene,2000,Angrist and Pischke,2008;Wooldridge,2010),机器学习文献有某些概念区别(可参阅Mullainathan and Spiess,2017)。在机器学习研究考虑的情形下,往往有大量的协变量,有时甚至超出样本中的单元数量。机器学习文献并不假设给定协变量的结果的条件分布遵从特定的参数模型。每个协变量的条件期望(在线性回归模型中对应着参数)的导数未必是重点所在,重点其实在于样本外预测及其准确性。此外,相比经济学研究的许多应用场景,机器学习文献中每个协变量的条件期望呈单调变化也不那么重要。机器学习文献通常更关注的是,条件期望或许是极端的非单调函数,存在某些有重要意义的高阶的相互作用。
关于条件期望估计的计量经济学研究文献非常多。估计g(·)的参数模型经常采用最小二乘法。自比伦斯(Bierens,1987)以来,在需要更多灵活性的时候,核回归方法已成为流行的替代方法,序列方法或筛法也被广泛采用(有关综述可参见Chen,2007)。这些方法有充分的大样本特性,允许构建置信区间。但在高维协变量的情形下,简单的非负值核回归方法被认为表现很差,有阶数达到Op(N-1/K)的差异g^(x)-g(x)。这一比率的改进可以利用更高阶的核回归,并假设存在g(·)的许多导数。然而对高维协变量的实际操作结果表明这些方法并不理想,核回归在计量经济学的应用通常也限于处理低维场景。
核回归等传统方法与随机森林等现代方法的表现差异,在有着大量关系不大的协变量的稀疏场景下尤其突出。随机森林方法能够有效应对稀疏性,忽略大量的无关特征,而采用传统核回归方法会因为这些协变量而浪费大量自由度。虽然核回归方法在处理无关协变量时有可能调整适合协变量的特定带宽,但在实践中这方面的尝试很少见。第二个问题是,现代方法尤其擅长发现严重的非线性和高阶的相互作用。但此类方法在高阶相互作用场景中的成功应用案例,不能让我们忽略在许多经济数据中高阶相互作用的重要性。例如在预测个人收入时,我们会预期回归函数对教育和早期收入等重要预测变量来说是单调变化的,即使对同质性子群体也是如此。由此意味着,基于线性化的模型在此类情形下会比其他模型表现更好,这不同于单调变化不太可能出现的其他情形,如图像识别问题。局部线性随机森林方法的表现优于标准随机森林方法,也出于类似的原因(Friedberg et al.,2018)。
我们将讨论四类具体方法,当然机器学习的其他方法还有很多,包括基本方法的变体。我们首先介绍把协变量作为线性来考虑的模型,要解决的问题完全关于正则化。其次是利用回归树和随机森林来分割协变量空间的方法。第三是探讨神经网络方法,它曾是20世纪90年代少数计量经济学文献的关注点(Hornik et al.,1989;White,1992),近期则成为机器学习文献中以不同形式表现出来的重要课题。第四是介绍提升算法的一般原则。
3.1正则化的线性回归:LASSO方法、岭回归和弹性网络
设想我们要对有如下线性表达式的条件期望做近似模拟:
 |
这三种特殊情形,即子集选择、LASSO方法和岭回归方法之间有两个重要的概念区别(近期的讨论参见Hastie et al.,2017)。首先,最优子集和LASSO方法都会带来若干回归系数完全等于0的稀疏解。相反,对于岭回归估计量,所有回归系数的估计值通常都不为0。得到稀疏解并不总是重要的,而且这些解中隐含的变量选择经常被过度解释。其次,最优子集回归有计算难度(NP难题),因此不适合N和K很大的情形,虽然最近在这方面的研究有所突破(Bertsimas et al.,2016)。LASSO方法和岭回归方法有贝叶斯解释。在正态模型下,岭回归提供了Xi给定时Yi的条件分布的后验均值和后验众数,以及参数的正态先验分布。而LASSO方法对给定的Laplace先验分布提供了后验众数。不过相比规范的贝叶斯分析方法,现代研究文献中的惩罚项的系数λ是通过样本外交叉验证进行选择,而非来自对先验分布的主观选择。
3.2回归树与随机森林方法
回归树方法(Breiman et al.,1984)及其拓展随机森林方法(Breiman,2001a)已成为看重样本外预测能力的情形下,灵活估计回归函数的极为流行的高效方法。人们认为它们有着很好的即时可用表现,无须做精细调适。例如,给定样本(Xi1 ,…,XiK,Yi),其中i= 1,…,N,这里的想法是把样本分割成子样本,在各个子样本中估计回归函数,得出平均结果。样本分割是顺序性质的,基于某个协变量XiK超出门槛值c的标准。我们先看整个训练样本,设想根据某个特征或协变量k和门槛值c分割样本。在分割之前,样本内的误差平方和为:
 |
分别是两个子样本的平均结果。我们下面这样分割样本(即选择k和c):使得对于所有协变量k= 1,…,K,以及所有门槛值c ∈ (-∞,∞),均方误差Q(k,c)为最小。然后我们重复这一操作,对子样本(或称叶,leaves)也都进行最优化。在每次分割后,得到的均方误差被进一步缩小,或者保持不变。接着我们还需要某些正则化,以避免次数过多的样本分割导致过度拟合。一种方法是在平方残差之和中加入一个惩罚项,与子样本(叶)的数量呈线性关系。这一惩罚项的系数将通过交叉验证来选择。在实际操作中,我们会估计一个很深的树模型,然后利用交叉验证来选择最优深度,将其剪枝到较浅的状态。先种植再剪枝的工作顺序,可以避免错过那些需要细微相互作用才能显出优势的样本分割。
采用单一树模型的一个好处是,便于解释和阐述结果。树模型的结构一旦定义,每片树叶的预测就是样本平均值,样本平均值的标准差很容易计算。但一般而言,一片树叶的样本平均数未必是新测试集中同一片树叶的均值的无偏估计。由于树叶的选择过程利用了数据,训练数据中树叶的样本均值往往会比独立测试数据显得更趋于极端(就偏离总体样本均值的程度而言)。有研究认为,可以通过样本分割来避免这种问题(Athey and Imbens, 2016)。如果预测需要置信区间,则研究者可以简单地把数据对半分开,一半数据用于构建回归树,然后把这个树模型隐含的分割方法用于另一半数据,那里的给定树叶的样本均值应该是真实均值的无偏估计。
树模型比较容易阐述,但应该注意不要过度阐述树的结构,包括用于样本分割的变量的选择。对此,计量经济学关于遗漏变量偏差的标准直觉可以提供帮助。与结果有强烈联系的特定协变量在样本分割中可能没有出现,因为树在分割中采用的协变量与它们存在高度相关。
对树模型的一种阐述是将它作为核回归的替代办法。在每个树模型内部,对一片树叶的预测只是树叶内部得出的样本平均结果。因此,我们可以把树叶理解为其中给定目标观测值的最邻近值集,从单一回归树中得出的估计量是选择目标点的最邻近值的非标准方法得出的匹配估计量。具体来说,邻近区域在决定哪些观测值符合邻近的定义时,会优先考虑部分协变量。图1展示了核回归与树模型匹配算法在两个协变量下的差异。核回归将产生一个围绕目标观测值的邻近区域,基于它到每个点的欧式几何距离;树模型得出的邻近区域则是矩形状态。此外,目标观测值或许并不位于矩形的中心。因此,对于任何给定测试点x,单一树模型通常不是预测结果的最佳方法。在需要对特定目标观测值做专门预测的时候,可以采用一般化的基于树模型的方法。
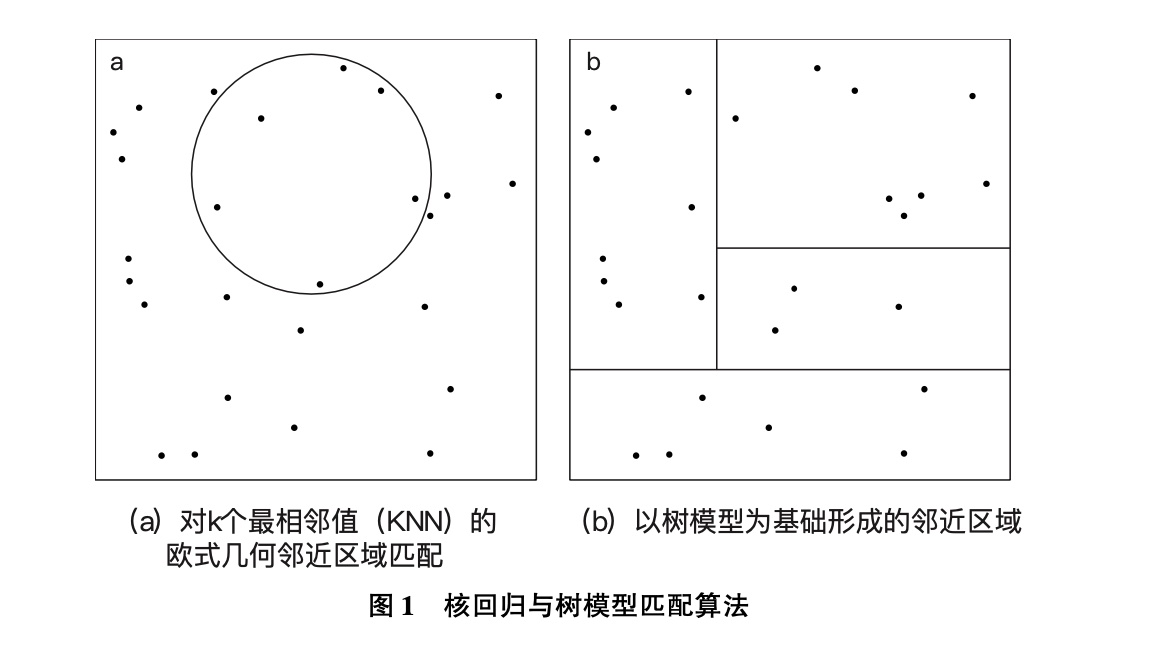 |
为更好地估计μ(x),可采用基于回归树算法的随机森林模型(Breiman,2001a)。随机森林模型解决的一个关键问题是,树对应的被估计回归函数是不连续的,比我们设想的有更多的显著跳跃。随机森林模型通过对很大数量的树模型做平均处理来引入平滑性。这些树彼此有两方面的差异。首先,每个树模型都不是基于原始样本,而是引导样本(bootstrap sample,也称为装袋样本)或者是数据的子样本(Breiman,1996)。其次,每个阶段的分割不是对所有可能的协变量做最优化,而是对协变量的一个随机子集做最优化,因此会改变每次分割。这两个修订导致了树之间具有足够差异,使得平均值相对平滑(虽然依旧不连续),更重要的是比单一树模型有更强的预测能力。
随机森林已经成为非常普遍的方法。它的一个重要优势在于,相比深度学习神经网络等更复杂的方法,它们要求较少的调适,并有很好的即时可用表现。在有着与结果无关的大量特征,即存在稀疏性的情形下,随机森林与回归树方法特别有效。样本分割通常忽略这些协变量,由此使得即便在有大量特征的情形下,模型表现依然良好。事实上如果与核回归方法做比较,对随机森林方法的表现做改进的一条可靠途径就是加入没有预测力的无关协变量。这样做将迅速降低核回归方法的表现,但不会严重影响随机森林方法,因为随机森林方法原本就不太重视这些协变量(Wager and Athey 2017)。
虽然自布雷曼的初始研究以来,对随机森林的统计分析显得不容易把握,但近期研究表明(Wager and Athey,2017),随机森林方法的特定变体可以得到以μ(x)真实值为中心呈渐进正态分布的μ^(x)的估计值;此外,该研究还提供了对估计量方差的估计,由此可以构建中心置信区间。该研究讨论的变体方法采用子样本抽样方法,而非装袋抽样,而且每个树模型的构建利用了两个不相交的子样本,第一个用来定义树模型,第二个用来估计每片树叶的样本均值。这一诚实的估计对渐进式分析非常关键。
 |
随机森林可以在几方面同传统计量经济学方法联系起来。我们再回到与核回归的比较上,由于每个树模型是一种形式的匹配估计量,森林则是匹配估计量的平均。正如图2所示,通过树模型的平均,对每个点的预测将围绕测试点(除靠近协变量空间边界的以外)。然而,森林方法是通过数据驱动的方式选择匹配,因而优先采用更重要的协变量。对随机森林的另一种阐述方式是,它们会产生类似于核回归使用的权重函数(如Athey et al.,2016b)。例如,核回归对点x做的预测是把邻近点做平均,但对越邻近的点赋予的权重越大。随机森林方法则是对许多树的平均,与较远的点相比,会更多包含邻近的点。我们可以通过测算特定观测值与测试点同处一片树叶的树的比例,针对给定测试点形式化地推导出权重函数。于是随机森林预测可以表述如下:
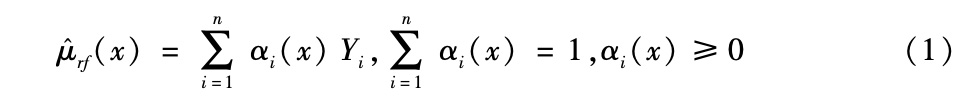 |
其中权重αi(x)代表森林方法在预测x时给第i个训练样本赋予的权重。典型的核回归权重函数与随机森林权重函数的区别在于,森林的权重是适应性的,如果某个协变量的影响很小,就不会用于叶的分割,权重函数在该协变量的距离变化上也就不会非常敏感。
近期的随机森林研究已扩展至因果效应的情形,包括平均或单元层面(Wager and Athey,2017),以及对可以利用最大似然方法或者广义矩方法(GMM)的一般经济学模型的参数估计(Athey et al.,2016b)。对后者而言,其实是在操作中把森林方法阐述为创造一个权重函数。新出现的一般化随机森林算法包含两个步骤:第一步是构建森林;第二步是对每个测试点做广义矩模型估计,与测试点经常出现在相同叶的邻近点在估计中被赋予更大权重。若采用恰当的诚实估计模板,森林方法可以得出具有渐进正态分布的参数估计结果。通用的随机森林方法可以理解为局部最大似然方法的一般化[由Tibshirani and Hastie (1987)的研究引入],而在核回归的权重函数中,对于更靠近特定测试点的观察值,会赋予比更远离的点更大的权重。
随机森林方法的一个缺点在于,它们既不能很有效地反映线性或二次效应,也无法利用基本数据生成过程的平滑性。此外,在靠近协变量空间的边界位置,它们可能产生偏差,因为随机森林的组成叶不能集中在靠近边界的点。传统计量经济学在不连续回归设计的分析中也遇到过这一边界偏差问题,例如,以学区的地理边界或者考试成绩录取线来决定参与某个学校或学习项目的资格等(Imbens and Lemieux,2008)。计量经济学研究(如匹配问题研究)提出的解决方案是采用局部线性回归,给邻近点赋予更大权重(Abadie and Imbens,2011)。设想在接近边界时,条件均值函数呈递增,于是局部线性回归可以帮助矫正如下事实:在靠近边界的测试点上,大多数样本点会位于这样一个区域,该区域的条件均值低于边界上的条件均值。另有研究把一般随机森林分析扩展到局部线性森林分析(Friedberg et al.,2018),在回归中采用了随机森林推导出的权重函数。如果用最简单的形式来介绍,局部线性森林方法直接采用森林权重函数αi(x),并将它用于如下局部回归:
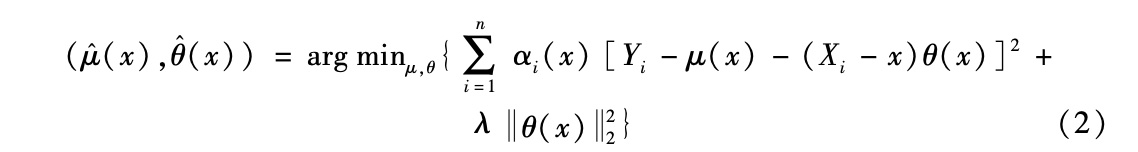 |
修订树模型的结构使之包含回归校正可以改进模型的表现,这从本质上看是通过预测局部回归的残差来对样本分割做最优化。如果回归可以反映条件均值函数的大致形态,例如单调性或二次结构,那么这一算法的表现可能优于传统随机森林方法,并且可确立渐进式正态分布。图3展示了局部线性森林为何可以改进普通随机森林方法。通过以随机森林估计的核来拟合局部线性回归,得出的预测即使在较小数据库中也能匹配简单多项式函数。与之相比,随机森林方法往往会产生偏差,特别是在靠近边界处,而且在小数据库中更多表现出阶梯函数的形状。图3展示的是一维场景的效果,而随机森林方法相比核回归的一个优势在于,这些校正可以在多维场景中发生,并依然保留自己的传统优势:揭示协变量之间更多复杂的相互作用。
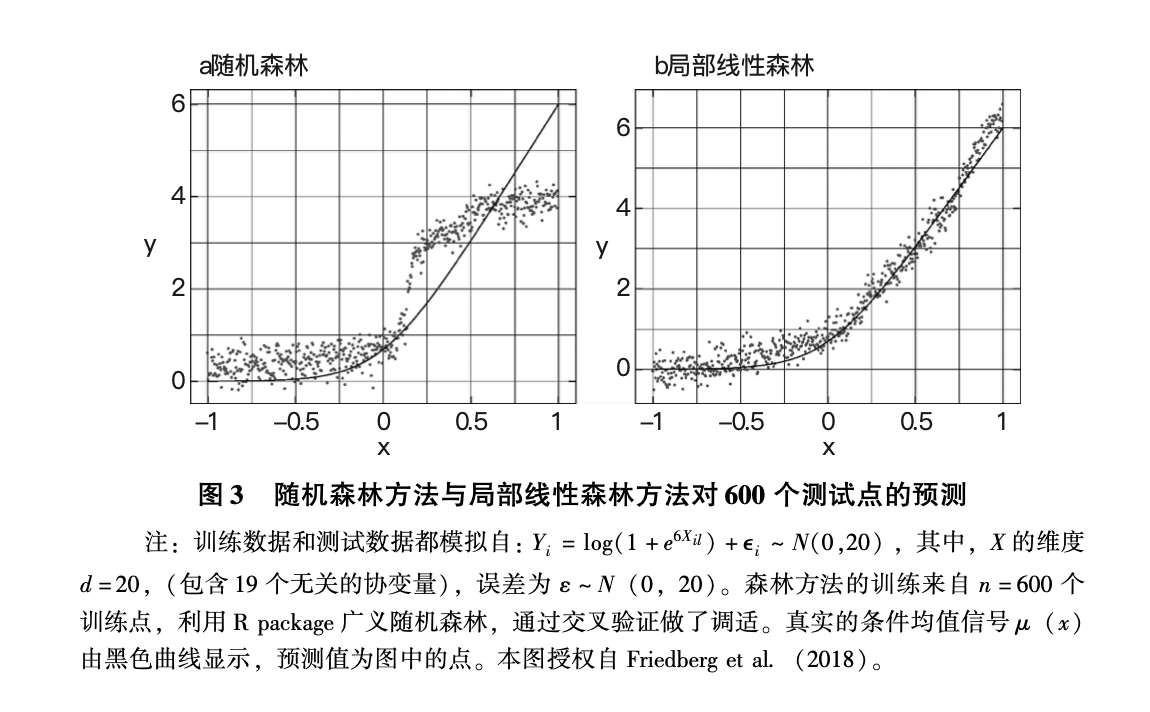 |
3.3深度学习与神经网络
神经网络及相关的深度学习方法,是估计回归函数的另一个普遍而灵活的途径,在有极大量特征的复杂情形下表现得尤其成功。但在实践中,相比随机森林等方法,这些方法要求很大量的调适,才能对特定应用场景产生良好效果。神经网络在20世纪90年代的计量经济学文献中有过探索,但当时并没有流行起来(参见Hornik et al.,1989;White,1992)。
我们可以考虑一个简单的案例,给定K个协变量(特征)的Xik,我们为K1个隐藏变量或未观测变量Zik(隐藏节点)建模,它们与原始协变量呈线性关系:
 |
虽然仅靠单层的许多节点,我们已经能模拟丰富的函数类型,但神经网络的深度还是会大大提高实践操作中的灵活度。多层网络的渐进性质近期得到了理论研究的确认(Farrell et al.,2018)。在应用中,学者们采用了包含很多层次(10层乃至更多层)以及数百万个参数的模型:
我们看到,在这种情形下层次较少的浅模型在大约2 000万个参数时会导致过度模拟,而深模型在超过6 000万个参数时仍能提供帮助。这说明利用深模型在模型能够学习的函数空间上具有实用优势。(LeCun et al.,2015,第289页)
在多个隐藏层次和大量隐藏节点的情形下,需要对参数估计做细致的正则化,或许是利用一个惩罚项,该项与模型的线性部分的系数平方之和成比例。网络的架构同样很重要。与之前的设定一样,可以让特定层次的隐藏节点成为之前层次的所有隐藏节点的线性函数,或者根据实质性考虑(substantive considerations,如协变量在某个尺度上的接近,例如像素在图片中的位置)将其限定在某个子集里。此类卷积网络方法的使用非常成功,但要求更加细致的调适(Krizhevsky et al., 2012)。
对网络中参数的估计是基于残差平方和的近似最小化,加上模型复杂度决定的一个惩罚项。这一最小化问题很有难度,特别是在多个隐藏层次的情形下。学者们选择了反向传播算法(back-propagation algorithm)及其变形,以此计算目标函数中单元层次项的参数的确切导数(Rumelhart et al.,1986)。这些算法巧妙地利用了各个层次之间存在上下结构,且每个参数都只进入一个层次的事实。然后这些算法再利用本文第2.6节介绍的随机梯度下降方法(Bottou,1998,2012; Friedman,2002)作为寻找近似最优解的有效计算方法。
3.4提升算法
提升(Boosting)是对简单的监督学习方法的表现做改进的一种通用技巧(详细介绍见Schapire and Freund,2012)。如果我们关心有大量特征时对结果的预测,并假设我们有一个很简单的预测算法,即基础学习器(learner)。例如我们有一个包含3片树叶的回归树模型,即基于两次分割的回归树模型,通过相应树叶的平均结果来估计回归函数。这种算法本身不会在预测效果上得出非常有吸引力的预测变量,因为它最多只会用到许多可能特征中的2个。提升算法会采用如下方式对基础学习器做改进。针对上述简单的3叶树模型,得出训练样本中所有单元的预测残差Yi-Y^(1)i。然后我们把同一个基础学习器(即2次分割的回归树模型)用于对残差的结果分析(并采用相同的原始特征集)。令Y^(2)i代表综合第一步与第二步得出的预测结果。在给定这个新的树模型后,我们可以计算出新的残差Yi-Y^(2)i。然后,我们重复该步骤,利用新的残差作为结果,再构建一个2次分割的回归树模型。我们可以这样重复操作许多遍,利用不断更新的残差对基本模型做多次反复估计,从而得出预测结果。
如果我们在有着L次分割的回归树模型里采用上述提升算法,则得到的预测量能够模拟可表述为同时有L个原始特征的函数之和的任何回归函数。因此如果L=1,我们就能模拟在特征上具有可加性的任何函数,如果L=2,我们就能模拟在(允许一般二阶效应的)原始特征的函数上具有可加性的任何函数。
提升算法还能适用于回归树模型之外的基础学习器。这里的关键是选出恰当的基础学习器,容易多次反复适用,而不会遭遇计算问题的困扰。
4.用于分类问题的监督学习
分类问题(classification problem)是监督学习研究文献的一个重要分支领域的关注点。该问题是指给定带有特征向量Xi与标签Yi(一个无序的离散结果)的观测集,目标是找出根据特征把新单元指定到其中一个标签的函数。这非常类似于计量经济学中的离散选择分析:学者们设定统计模型,其中隐含了根据协变量(特征)为结果赋予特定值的概率。如果给定这一概率,当然就很容易预测出一个特定标签,即赋值概率最高的标签。然而,这两种方法也存在若干差别,其中一个关键差别在于,在分类问题的研究中,重点通常仅在于分类,即选出单一的标签。给定每个标签的概率,我们固然可以做分类,但没有这样的概率也可以做分类。事实上,许多分类方法并不首先估计每个标签的概率,因此对于要求掌握此类概率的情形并不直接适用。还有一个现实中的差别在于,分类研究文献经常关注的场景是协变量最终允许我们有极高的把握分派标签,而不是针对即便用最好的方法也带有较高误差率的场景。
分类问题的一个典型例子是数字识别。例如针对一个有16个或256个黑白像素点的集合编码生成的图片,要求把图片区分到0~9这10个数字对应的各自类别。在此情形下,机器学习方法表现得极其成功。在20世纪90年代,支持向量机算法(Support vector machines,SVMs)远远领先于其他方法(Cortes and Vapnik,1995)。近来,深度卷积神经网络(convolutional neural networks)进一步改进了误差率(Krizhevsky et al.,2012)。
4.1分类树与森林
我们很容易对树与随机森林方法做出修订,把重点从回归函数估计改为分类任务(更一般的讨论参见Breiman et al.,1984)。这里我们再度从样本的2叶分割开始,基于单一的协变量超过或不超过一个门槛值。我们通过协变量和门槛的选择使样本分割最优化。回归问题与分类问题的差异在于目标函数:测算特定分割带来的改进。在分类问题中,这被称为杂质函数(impurity function),它测算的是,作为某一给定树叶中被赋予特定标签的单元比例的函数,该树叶的杂质度有多少。如果只有2个标签,则我们可以简单地将其标记为0和1,把问题阐述为对条件均值的估计,并利用残差平方的平均值作为杂质函数。但这自然不能普遍用于多标签的情形。因此,更为普遍采用的杂质函数作为M个比例p1,…,pM的函数,是如下基尼杂质函数:
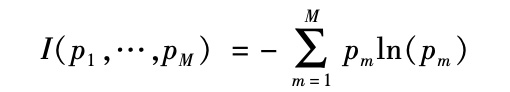 |
如果树叶是纯的,也就是说,该树叶中包含的所有单元具有相同标签,则以上函数将被最小化;如果所有标签所占的比例都等于1/M,则杂质函数会被最大化。正则化通常也是利用反映树叶数量的惩罚项来完成。在前文的回归问题中介绍的从单一树模型向随机森林的拓展方法,也适用于分类问题的处理。
4.2支持向量机与核
支持向量机是分类问题中采用的另一类灵活方法(Vapnik,2013;Scholkopf and Smola,2001)。支持向量机可以拓展到回归分析中,但用于分类问题显得更为自然,而且为简化起见,我们这里只介绍2个可能标签的情形。设想我们有N个观测值的集合,带有K维向量的特征Xi,以及二元标签Yi∈{-1,1}(也可以采用0/1标签,但选择-1/1更为方便)。给定K维向量的权重ω(这里通常称为参数)和常数b(在SVM研究文献中通常称为偏差),我们将定义一个超平面x∈R,使得:ωTx+b=0。我们可以认为,这个超平面给出了一个二元分类器的定义:sgn(ωTxi+b)。对于ωTx + b ≥ 0的单元,分类为1,对于ωTx+b<0的单元,分类为-1。下面我们考虑:对每个超平面[也就是对每一对(ω,b)],样本中发生的分类错误的数量。如果非常幸运,某些超平面不会出现分类错误。假如属于此类情况,通常有许多这样的超平面,我们从中选择与最近单元的距离最大化的一个超平面。通常会有少数单元与这一超平面存在相同距离(端距),它们就被称作支持向量(support vectors)。
我们可以把这表述为如下的最优化问题:
 |
5.非监督学习
非监督学习是机器学习文献的第二个主要课题。对于这一情形,我们有几个不涉及标签的例子。我们可以将它理解为,有关协变量的若干观测值,但没有结果值。我们关心的内容可能是如何把样本分割为子样本或聚类,或者估计这些变量的联合分布。
5.1K均值聚类
在这种情形下,目标是给定带有特征Xi的观测值集合,把特征空间分割为子空间。这些聚类可以用于根据子空间的成员创造新的特征。例如,我们可能希望利用样本分割在每个子空间中估计简约模型,还可能希望利用聚类成员的方式把样本划分成不同类型的单元,使它们接受不同的干预。这是个不寻常的问题,因为没有自然标准来评价特定解是否优于其他解。在更传统的计量经济学和统计学中与之有密切联系的一种方法是混合模型(mixture model),产生样本的分布是通过不同分布函数的混合来构建的。这些混合成分在本质上类似于聚类。
K均值算法(K-means algorithm)是这方面的一种主要方法(Hartigan and Wong,1979;Alpaydin,2009)。设想我们希望把特征空间分割为K个子空间或聚类,我们希望找出质心(centroids)b1,…,bK,并根据各个单元与质心的邻近程度,将其分派到各个聚类。基本的算法设计如下,首先我们有K个质心的集合b1,…,bK,有特征空间的各个元素,并在这个空间中充分铺展。给定一组质心后,我们把每个单元分派到相应聚类,使单元与聚类的质心之间的距离最小化:
 |
然后在以上两个步骤之间重复迭代。选取聚类的数量K较为困难,因为没有直接的交叉验证方法来评估某个值相对于其他值的表现。这个数字经常是根据实质问题而不是以数据驱动的方式来选择的。
目前有很多不同的非监督学习方法,包括我们将在第9节介绍的主题模型(topic models)。神经网络的非监督学习方法的变形尤其广泛地用于图像和视频的处理。
5.2生成对抗网络
我们设想一个联合分布的估计问题:对若干随机样本单元,给定Xi之上的观测值。近期发展出名为生成对抗网络(generative adversarial networks,GANs)的一种机器学习方法(Goodfellow et al.,2014,Arjovsky and Bottou,2017),其思想是找出一种算法,产生看起来类似于样本X1,…,XN的数据。一个关键的洞见在于,有一个有效的方法可以用来评估该算法是否成功,这类似于图灵检验。如果有成功的算法,则我们将无法辨别该数据是由算法生成的还是来自原始样本。于是我们可以通过训练算法数据与原始数据子样本的分类器来评估算法。如果某个算法取得了成功,则分类器将无法区分数据是来自原始数据还是算法数据。这样,生成对抗网络就可以利用分类算法的相对成功来改进数据生成的算法,事实上是让分类算法与生成算法相互竞赛。
此类算法还可以用来有效地选择旨在模仿真实数据的模拟设计。
6.机器学习与因果推断
计量经济学研究与机器学习研究之间的一个重要区别是,计量经济学往往关注简单预测之外的问题。在许多乃至大多数情况下,学者们关注平均干预效果或者其他因果参数或结构性参数(有关综述参见Imbens and Wooldridge,2009;Abadie and Cattaneo,2018)。对预测关系不大的协变量在此类结构性参数的估计中可能依然扮演重要角色。
6.1平均干预效应
这方面的一个经典问题是,在非混淆假设(unconfoundedness assumption)下估计平均干预效应(Rosenbaum and Rubin,1983;Imbens and Rubin,2015)。给定关于结果Yi的数据,一个二元干预变量Wi,协变量矢量或者特征Xi,一个普通被估计量,平均干预效应的定义为:τ=E[Yi(1)-Yi(0)],其中Yi(w)是单元i的干预方案为w时产生的潜在结果。如果满足非混淆假设,即确保潜在结果独立于根据协变量所做的干预安排:
 |
为估计平均干预效应,我们可利用第一个表达式估计条件结果期望μ(·),利用第二个表达式估计倾向得分(propensity score)e(·),或利用第三个表达式同时估计条件结果期望与倾向得分。给定某个表达式选项后,问题将是选择进入表达式的特定条件期望的恰当估计量。例如,如果我们希望利用第一个表达式并考虑采用线性模型,则利用LASSO或子集选择方法会比较自然。但有研究指出(Belloni et al.,2014),这种策略得出的统计性质可能很差。当目标是估计μ(·)时,对于将特定条件期望的恰当估计量放入表达式来说是最优的特征集合对估计τ来说则未必是最优的。原因在于,在回归中遗漏与干预方案Wi高度相关的协变量可能导致巨大偏差,即使它们与结果的相关关系并不是很强。因此,在模型选择最优化中只着眼于预测结果并不是最佳办法。上述研究建议采用的协变量选择方法是,同时选出对结果有预测能力的协变量和对干预方案选择有预测能力的协变量,并指出这会显著改善τ对应的估计量的统计性质(Belloni et al.,2014)。
更近期的研究侧重于采用灵活且双重稳健的方法,把条件结果期望μ(·)的估计与倾向得分e(·)的估计综合起来(Robins and Rotnitzky,1995;Chernozhukov et al.,2016a,b),以及采用其他方法,把条件结果期望μ(·)的估计与协变量平衡(covariate balancing)综合起来(Athey et al.,2016a)。协变量平衡受到了机器学习中另一种常见方法的启发,把数据分析构建为最优化问题。在此情形下,最优化过程不是估计原有的倾向得分e(·),而是直接优化观测值的权重分配,使得干预组和控制组的协变量有相同均值(Zubizarreta,2015)。即使倾向得分函数过于复杂,难以很好地估计,这一方法依然能够为平均干预效应提供有效估计。由于传统的倾向得分权重分配需要依据对倾向得分的估计,若倾向得分估计不稳定,可能导致平均干预效应的估计有较高的差异性。另外,在有着大量潜在混杂因素的场景下,采用正则化来估计倾向得分可能导致遗漏那些作用较弱但仍会导致偏向的混杂因素。因此,当有大量较弱的混杂因素时,直接对平衡权重做最优化可能更加有效。
在非混淆假设下估计平均干预效应,可视为计量经济学中一个更为普遍的主题的特例。通常而言,经济学家更关心对因果效应的准确估计,而非预测能力(更细致的讨论参见Athey,2017,2019)。在工具变量模型中,从普通最小二乘回归到两阶段最小二乘回归的第二阶段,拟合优度经常会大幅下降。然而,对因果效应的工具变量估计仍可以用来解答经济学感兴趣的问题,所以预测能力的上述损失并不是那么要紧。
6.2正交化与交叉拟合
机器学习方法在应用于参数估计的许多领域时,会遇到一个共同现象,通过两个简单的技巧,可以改进模型实际表现和理论支持。这两个技巧都涉及利用机器学习来估计多余参数(nuisance parameters)。我们可以通过平均干预效应的估计来展示这一点。利用上述公式(3)的第三个表达式,一个有效的半参数估计量的影响函数为:
 |
例如,每个多余部分μ^(·)和e^(·)都能够以接近N-1/4的速率收敛,这比平均干预效应的估计慢一个数量级。这可能有用,因为Ψi利用了正交化,在构造上,估计多余部分时形成的误差同Ψi的误差形成正交。若干论文更一般性地探讨过这一理念(理论上的分析参见Chernozhukov et al.,2018a,c)。在非混淆假设模型中估计异质性效应以及工具变量模型的应用,可参见本文作者的其他论文,包括我们2016年的论文(Athey et al.,2016b)。
上述系列论文探讨的第二个理念是,利用样本分割、交叉拟合(cross-fit-ting)、包外预测(out-of-bag prediction)以及留一估计(leave-one-out estimation)等技术,模型表现可以得到改进。这些技术都有相同的最终目标:为构建观察对象i的影响函数Ψ^i,对多余参数的估计,在平均干预效应分析中为μ^(w,Xi)和e^(Xi),应该不采用观测对象i的结果数据。在使用随机森林方法估计多余参数时,这点是显而易见的,因为包外预测(随机森林统计包中的标准做法)采用的树模型构建就没有使用观测对象i。用其他机器学习模型估计多余参数时,交叉拟合方法或样本分割方法主张把数据划分为折叠(folds),然后在留出折叠(left-out fold)中预测多余参数。当折叠的数量与观测对象同样多时,这又被称为留一估计。
以上两个课题对传统的小数据应用是有帮助的,当我们把机器学习用于估计多余参数时(因为有太多协变量),它们的作用明显变得更为突出。首先,过度拟合的问题此时更令人担心,尤其是当模型非常灵活时,单一观测对象i就可能对协变量Xi的预测值产生强烈影响。交叉拟合能帮助解决这一问题。其次,我们应该能预见,在协变量数量相对于观测值数量很大时,对多余参数的准确估计更难做到。此时,正交化可以增强估计对误差的稳健性。
6.3异质性干预效应
机器学习方法能发挥极大作用的另一个地方是发现异质性干预效应,对此我们特别关注与可观测协变量有关的异质性。这方面的问题包括:哪些个体从一次干预安排中获益最多?哪些个体的干预效应为正?干预效应如何随协变量发生改变?弄清楚干预效应的异质性能够帮助深化基本的科学认识,或者评估最优化的政策安排(更多的讨论可参阅Athey and Imbens,2017b)。
延续本文第6.1节关于潜在结果的分析,我们对条件平均干预效应(CATE)做如下定义:τ(x) = E[τi|Xi = x] , 其中,τi=Yi(1)-Yi(0),是针对个体i的干预效应。在第6.1节介绍的非混淆假设条件下,条件平均干预效应被识别。需要注意,τi对任何单元均无法观测,这一“基本因果推断问题”(Holland,1986,第947页)乃是异质性干预效应估计与结果预测之间有明显差异的根源,后者对每个单元通常是可以观测的。
我们下面聚焦于三类问题:(a)学习异质性干预效益的低维表达式,并对这种异质性开展假设检验;(b)学习对τ(x)的一种灵活的非参数估计;(c)根据协变量x把单元分配到干预组或控制组的最优策略的估计。
在采用机器学习方法处理因果参数时,一个重要课题涉及模型选择中的准则函数(criterion function)。预测性模型通常利用一个均方误差(MSE)来评估表现:Ei[Yi-μ^(Xi)]2/N。虽然对于独立集合中的均方误差的总体期望来说,留出测试集中的均方误差是个有噪声的估计值,样本平均的均方误差则是无偏的近似值,不依赖更多假设(除观测值的独立性以外),而且测试集中的误差平方的标准差准确反映了估计中的不确定性。与之相比,对观测类研究中的条件平均干预效应估计而言,则会很自然地采用干预效应的均方误差作为准则函数,即Ei[τi-τ^(Xi)]2/N,其中τ^(x)是对条件平均干预效应的估计。然而这一准则并不可行,因为我们观测不到单元层面的因果效应。此外,在观测类研究中,没有对这一准则函数简单且与模型无关的无偏估计。因此,相比更加关注预测表现的情形,在关注结构参数或因果参数的情形下,对估计量做比较乃至开发正则化策略的难度都会大得多。
找到有效交叉验证策略面临的上述困难并非都不能克服,但这要求针对所要研究的问题,细致地调整和修订基本的正则化方法。有学者建议采用几种不同准则来对协变量空间做最优化分割以及交叉验证(Athey and Imbens,2016)。这里的第一个发现是,在选择模型时,只需要对模型做比较分析即可。例如对τ^′(x)和 τ^ ″(x)这两个估计量做比较的时候,难以估计的τ2i 项会被抵消,剩余的项将与τi呈线性,并可以估计出τi的期望值。若采用如下的转换结果定义(Athey and Imbens,2016):
 |
根据这一发现,学者们建议对条件平均干预效应的估计量的相对均方误差采用几种不同的估计量(Athey and Imbens,2016)。由此发展出了一种名为因果树(causal tree)的方法来学习干预效应异质性的低维表达式,从而能够给估计的参数提供可靠置信区间。这篇论文根据回归树方法,给协变量空间制造分区,再估计分区中每个元素的干预效应。不同于使预测最优化的回归树模型,这里的分区规则最优化是为了找到与干预效应异质性有关的分割。此外,该方法依赖于实际的样本分割,一半的数据用于估计树的结构,另一半(估计样本)用于估计每片树叶的干预效应。与标准回归树模型类似,这种树模型也利用交叉验证来剪枝,但是,对树模型在留置数据(held-out data)中的表现进行评估的准则是基于干预效应的异质性而非预测的准确度。
因果树方法的某些优点类似于回归树模型,比较容易解释,在随机实验的场景中,对每片树叶的估计就是样本的平均干预效应。因果树方法的一个缺陷在于,树模型的结构有一定主观性,数据空间的许多分区可能呈现干预效应的异质性,采用略有不同的数据子样本可能导致不同的估计分区。在浅树模型的树叶中采用的简单估计方法也可以用于其他类型的模型,这一思想的早期阐述参见泽莱斯等人(Zeileis et al.,2008),但该论文没有提供理论支持或置信区间。
为了某些目的,我们有时需要对τ(x)进行平滑估计。例如,如果必须对带有协变量x的特定个体做干预决策,则回归树可能对该个体给出有偏估计,因为它或许不处在树叶的中心,而且树叶或许包含在协变量空间上距离较远的其他单元。在传统计量经济学研究中,非参数估计可以通过核估计或匹配技术来完成。可是在有大量协变量的情形下,这些技术的理论和实际的统计性质较差。有研究为此引入了因果森林方法(Wager and Athey,2017),从本质上说,因果森林是大量因果树模型的平均,这些因果树因为子采样而各不相同。与预测森林方法类似,因果森林方法可以视为最近相邻匹配方法(nearest neighbor matching)的一个版本,不过是以数据驱动的方式来决定协变量空间的哪些维度是重要的匹配考虑。以上研究确认了该估计量的渐进正态性(只要树估计是诚实的,利用了每个树模型的样本分割),并提供了估计方差的估计量,由此可以构建置信区间。
采用因果森林方法遇到的一个挑战是不容易描述结果,因为被估计的条件平均干预效应函数τ^(x)可能非常复杂。但在某些情形下,我们可能希望对更简单的假设进行检验,例如,条件平均干预效应排名前10%的个体相比其他总体样本有着不同的平均干预效应。有学者为此类假设的检验找到了某些方法(Chernozhukov et al.,2018b)。
正如前文对回归森林方法的论述,因果森林方法也得到了拓展,以分析可以用最大似然方法或广义矩方法估计感兴趣参数的非参数模型中的异质性(Athey et al.,2016b),其中一个应用情形是针对工具变量。另有研究把局部线性回归森林方法拓展到处理异质性干预效应的问题,使得函数τ(x)的正则性可以被更好地利用(Friedberg et al.,2018)。
在工具变量模型中估计参数异质性的另一种方法来自哈特福德等人(Hartford et al.,2016),这是基于神经网络算法,但对该估计量没有提供分布理论。如果我们假设异质性结构采取一种简单形式,则可以利用其他方法来估计条件平均干预效应。其中的一种方法是目标定位最大似然估计(Targeted maximum likelihood,van der Laan and Rubin,2006),也有人建议用LASSO方法来揭示异质性干预效应(Imai and Ratkovic,2013)。还有人(Künzel et al.,2017)建议采用一种利用元学习器(meta-learners)的机器学习方法。还有一个采用贝叶斯分析的常用替代方法是贝叶斯加法回归树(Bayesian additive regression trees,BART),由奇普曼等人(Chipman et al.,2010)开发,并被应用于因果推断(Hill,2011;Green and Kern,2012)。近来的一个有前途的方法是由两位学者(Nie and Wager,2019)提出的R学习器(R-leaner):首先利用灵活的机器学习预测方法来估计两个多余成分(条件结果均值与倾向得分),然后聚焦于损失函数,把我们感兴趣的因果效应从这些多余成分中分离出来。
弄清楚干预效应异质性的一个主要动机是,条件平均干预效应可以用于定义政策安排函数,也就是从个体的可观测协变量映射到政策安排的函数。定义政策的一个简单方式是估计τ^(x), 并对τ^(x)为正值的所有个体安排干预方案,这里的估计值应该加入因处于干预组或控制组带来的所有成本。有研究指出,这在某些条件下是最优选择(Hirano and Porter,2009)。对这种方法的一个担忧是,从估计τ^(x)使用的方法看,政策设计可能非常复杂,而且不能保证平滑性。
北川和捷捷诺夫(Kitagawa and Tetenov,2015)关注的是,在已知倾向得分的观测研究中,从复杂性有限的一类潜在政策中估计出最优政策。目标是选择政策函数,使得未能利用(不可行的)理想政策的损失最小化,他们将此命名为“政策遗憾值”(regret of the policy)。另有研究同样分析了复杂性有限的政策(Athey and Wager,2017),其中考虑了其他约束,如干预的预算约束等,并提出了估计最优政策的算法。该研究针对数据来自混淆假设下的观测类研究以及倾向得分未知的情形,提出了算法表现的边界,另外把分析拓展到了不满足非混淆假设的情形,例如有一个工具变量的情形。阿西和韦杰(Athey and Wager,2017)指出,利用从准参数有效性理论得出的结论,可以得出比机器学习研究更严格的表现边界,从而大幅缩小能够实现政策遗憾边界的算法集。针对无混淆假设的情形,该研究建议的政策估计过程可表述如下:
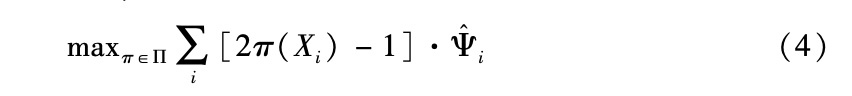 |
其中,Π是函数集合π:x→{0,1},Ψ^i的定义如前,并且利用了正交化以及交叉拟合方法。
最优政策估计的课题在机器学习文献中受到了一定重视,特别是针对非混淆假设下的观测类研究的数据。(*2.有关文献包括Strehl et al.(2010);Dudik et al.(2011,2014);Li et al.(2012,2014);Swaminathan and Joachims(2015);Jiang and Li(2016);Thomas and Brunskill(2016);Kallus(2017)。)另外,还有研究(Zhou et al.,2018)分析了2个以上干预组的情形,拓展了阿西和韦杰(2017)得出的效率结果。
机器学习方法针对该问题的一个发现是,公式(4)中的最优化问题可以改写为分类问题,并利用现成的分类工具来求解(有关细节可参阅Athey and Wager, 2017)。
7.实验设计、强化学习与多臂老虎机方法
机器学习方法在近期对实验设计(experimental design)做出了很大贡献,特别是在线上实验中,多臂老虎机方法(multi-armed bandits)变得更为流行。汤普逊抽样(Thompson sampling,Thompson,1933;Scott,2010)与置信上界(upper confidence bounds,UCBs,Lai and Robbins,1985)可被视为简单的强化学习(reinforcement learning)案例(Sutton and Barto,1998),在这类案例中,通过把更多单元分派给相应的干预组对成功的分派决策给予奖励。
7.1 A/B测试与多臂老虎机
传统上,大量实验的开展是把预定数量的单元分派到每个干预组中,通常情况下只包含2个干预组。在结果被测算出来后,会利用干预组的平均结果差异来估计平均干预效应。但这可能是非常缺乏效率的实验方式,如果我们把单元分派到我们已知有较大把握会弱于其他组的干预组,就会造成浪费。现代的在线实验方法则强调:要在探索新的干预方案与利用目前评估属于高质量的干预方案之间保持平衡。设想我们主要关心在现有干预集合中找到好的干预方案,而非评估整个干预方案集合的期望结果。此外再假设,我们在分派完成后能很快测算出干预结果,而且单元以顺序方式进入干预方案的分派。那么在观测到一半单元的结果后,我们可能会对哪些干预方案是最优候选方案形成基本印象。此时,如果把更多单元依旧分派给缺乏竞争力的干预方案,对探索和利用的目的而言都不会是最优选择,因为这样做不能帮助我们在候选的最优干预方案中进行识别,并让实验单元接受质量较差的干预方案。
多臂老虎机方法试图改进这种静态设计(Thompson,1933;Scott,2010)。在极端情况下,每个单元的分派取决于此时学习到的全部信息。给定这些信息,并给定每种干预方案的结果的参数模型以及这些模型的先验参数设定,我们就能估计出每种干预方案成为最优选择的概率。汤普森抽样认为,把下个单元分派到各种干预方案的概率应该等于该干预方案为最优选择的概率。这说明,对于我们确信不如其他干预方案的干预方案来说,给它分派干预组的概率会较低,而且最终会使所有的新单元都被分派到成功概率接近1的最优干预组中。
为便于直觉上的理解,设想有K种干预方案的情形,结果为二元形式,因此模型是一个二项式分布,各个干预组获得成功的概率为pk,k= 1,…,K。如果这些概率的先验分布是相同的,则干预组k的成功概率的事后分布为参数Mk+ 1和Nk-Mk + 1的贝塔值(此时在Nk次尝试中取得Mk次的成功)。由于贝塔分布很容易用模拟来近似,则干预组k是最优选择的概率(有最高的成功概率)应该为:pr(pk=maxKm=1ppm)。
我们可以简化计算,在看到几个新观测值之后,对分派概率做出更新。也就是说在一个批次的新观测值(都基于相同的分派概率)进入之后,再重新估算分派概率。从这个角度看,我们可以把标准的A/B实验理解为全部观测值组成一个数据批次的实验。由此便容易理解,至少在某些时候,更新分派概率、避免向表现较弱的干预组输送新的实验单元,会是一个更好的策略。
另一种途径是采用置信上界方法(Lai and Robbins,1985)。此时我们针对每个干预组的总体平均结果μk构建一个100(1-p)%的置信区间,然后对每个干预组收集置信区间的上界,把下一个单元分派到有最高置信上界值的干预组。随着我们得到的数据越来越多,1减去置信区间水平p的值将逐渐趋向于0。在利用置信上界方法时,如果我们希望在若干批次单元进入之后才更新分派概率,则需要更加小心。如果两个干预组有非常相似的置信上界,把大量单元分派到置信上界略高的干预组或许并不合适。若采用汤普森抽样法,此时会给两个干预组分派数量相近的单元。更一般地说,相比置信上界方法下的决定性分派,汤普森抽样下的随机分派在理论上具有随机推断能力的优势(Athey and Imbens,2017a)。
7.2背景老虎机方法
多臂老虎机方法的最重要拓展是针对如下情形,我们观测到的单元特征能被用于分派机制。如果干预效应是异质性的,且该异质性与单元观测到的特征有关,则根据这些特征把单元分派到不同干预组可能带来巨大好处(详细讨论可参阅Dimakopoulou et al.,2018)。
把协变量纳入考虑的一个简单办法是,为每个干预组的期望结果构建一个参数模型(奖励函数),利用当前数据做估计并由此推断:根据新单元的特征,特定干预组对新单元是最优选择的概率。从理论上讲,这是把单元的特征纳入考虑的一种直接方式,但有一些缺陷。主要的一个缺陷是,此类方法本身可能高度依赖模型的正确设定。有可能出现如下情形,某个干预组的数据带有单元特征的某种分布,却被用来预测特征非常不同的单元的结果(参见Bastani and Bayati,2015)。由此造成的风险是,如果用该算法估计从特征到结果的简单线性映射模型,则对于干预组从未观测到的某个特征空间区域,算法依然会认为干预组的结果有很大确定性。这可能导致算法一直不在该区域对实验组开展实验,导致它始终不能纠正错误,即使在大样本中也无法学习到最优策略。
因此,我们在构建联系特征与结果的灵活模型时应非常慎重。另有研究强调了利用随机森林方法避免对函数形式做假设的好处(Dimakopoulou et al.,2017)。
除上述议题外,背景老虎机方法(Contextual Bandits)中还涉及几个新的发现。由于分派规则作为特征的函数会随着更多单元的到来而变化,并通常会把更多单元分派到该规则在过去表现良好的协变量空间区域中的干预组,因此我们需要特别小心地消除奖励函数估计中的偏差。虽然有规范的随机化方法,此时仍会涉及观测类研究中对条件平均因果效应的稳健估计问题。受因果推断研究文献的启发,有一种解决办法利用倾向得分对结果模型赋予权重。有学者利用双重稳健估计[对倾向加权的结果(propensity-weighted outcome)建模]来分析背景老虎机方法的边界,并证明在若干真实世界数据库中,倾向加权改进了算法表现(Dimakopoulou et al.,2018)。
另一个发现是,利用简单的分派规则可能比较有效,特别是在早期的老虎机算法阶段,因为复杂的分派规则可能在后来导致干扰。具体来说,如果某个协变量与结果有关,并被用于分派机制,则后来的估计必须控制这一协变量,以消除其导致的偏差。因此在估计用于后来批次的单元分派的结果模型时,选择稀疏模型的LASSO方法会优于(依赖更多协变量的)岭回归方法。最后,灵活结果模型在某些场景下可能很重要;随机森林方法此时可以成为较好的替代选项。
8.矩阵填充与推荐系统
上述方法主要适用的情形是,我们观测到若干单元的信息,包括单一的结果以及一组协变量或特征,这在计量经济学研究中被称为横截面情形。而对计量经济学中所说的纵向数据或面板数据的类似场景,也有许多有趣的新分析方法。本节我们将介绍此类问题的一个经典版本以及某些特定方法。
8.1网飞问题
网飞大奖赛于2006年设立(Bennett and Lanning,2007),要求研究者利用数据训练来开发一种算法,通过电影评分的预测来改进网飞公司推荐影片的算法。研究者们获得的训练数据库包含影片与个人的特征,以及影片评分。对他们的要求是预测没有提供评分的“影片与个人”评分配对。由于奖金高达100万美元,这场竞赛及相关问题吸引了大量的关注,并使得解决此类场景的新方法的开发显著提速。获胜的方案和与之匹敌的解决方案有某些关键特征:首先高度依赖模型平均的方法,其次许多模型包含矩阵因子分解(matrix factorization)以及最邻近方法。
虽然初看起来,这似乎与计量经济学研究的问题类型相去甚远,但我们可以用类似形式对应计量经济学中的许多面板数据。对于学者们关注的二元干预的因果效应的情形,我们可以把已实现的数据(realized data)理解为包含2个不完整的潜在结果矩阵:一个是给定干预方案的结果,一个是给定控制方案的结果。于是,估计平均干预效应的问题可以对应为一个矩阵填充(matrix completion)问题。假设我们观测到N个单元在T个时期的结果,单元i在时期t的结果为Yit,二元治疗方案为Wit,并有:
 |
于是,估计因果效应的问题就变成了给矩阵输入缺失值的问题。
针对N和T都非常大,并有很大比例数据缺失的情形,机器学习研究发展出了多种有效的矩阵填充法。我们将在下一节介绍其中一些方法,并讨论它们同计量经济学研究的联系。
8.2针对面板数据的矩阵填充法
矩阵填充研究关注的是,如何对完整数据矩阵采用低秩的表达式。我们先考虑没有协变量的情形,即单元或时期不带有特征。令L代表期望值的矩阵,Y代表观测数据的矩阵。假设观测值等于完整数据矩阵中的对应值,但或许带有误差:
 |
其中,λ是通过交叉验证而选择的惩罚参数。此时之所以利用核范数,而非矩阵L的秩,主要是出于计算方面的考虑。利用弗罗贝尼乌斯范数(Frobenius norm,等于奇异值平方和)的办法行不通,因为这等同于矩阵的平方和,会导致把所有缺失值作为0输入。如果利用核范数,还能找到有效的算法来处理N和T数量很大的情形(参见Candès and Recht,2009;Mazumder et al.,2010)。
8.3计量经济学对面板数据的研究与综合控制方法
计量经济学文献从若干不同角度探讨过上述问题。面板数据研究在传统上关注固定效应方法,并将其归纳为包含多个隐藏因子的模型(Bai and Ng,2002,2017; Bai,2003),就本质而言与机器学习研究中的低秩因子分解是相同的。差别在于,计量经济学研究更加重视对因子的实际估计,并采用允许识别的正则化方法,通常假设有固定数量的因子。
综合控制(Synthetic Control)研究文献分析了类似情形,但重点在于矩阵Y中只有单一行缺失数值的情形。有研究(Abadie et al.,2010,2015)建议利用同一时期其他单元的结果的加权平均值作为输入数据。杜德琴科和因本斯(Doudchenko and Imbens,2016)则指出,上述研究(Abadie et al.,2015)采用的方法可以理解为根据其他单元的结果对最后一行做回归,并利用该回归结果来输入缺失值,又被称作垂直回归(vertical regression,Athey et al.,2017a)。这与项目评估研究中常见的水平回归(horizontal regression)不同,后者中最后时期的结果是根据较早时期的结果来做回归,并以此输入缺失值。矩阵填充法与水平回归和垂直回归都不同,原则上试图在输入缺失值的时候兼顾时间和单元上的稳定,并可以直接处理更复杂的数据缺失状态。
8.4面板数据中的需求估计
经济学和市场分析中有很多文献关注利用消费者的选择数据来估计其偏好。典型案例是分析消费者的离散选择,对于从预先设定的不完美替代选项集合中决定一件产品(有关回顾参见Keane,2013)。此类研究通常一次关注一类产品,并对少数产品之间的选择建模。研究重点往往是估计交叉价格弹性,从而可以分析企业合并和价格调整之类的反事实情形。虽然把个体偏好纳入可观测特征是普遍的做法,但此类模型中隐藏变量的数量通常较少。标准的模型设定首先是关于消费者i在时间t对产品j的效用:
 |
从机器学习的角度看,反映消费者选择的面板数据可以利用上述矩阵填充法来分析。模型会利用不同消费者有相似购买模式的产品以及对不同产品有相似购买模式的消费者来做推断。不过,此类模型通常不太适合分析两个产品相互替代的程度,以及分析反事实情形。
例如,雅各布斯(Jacobs et al.,2014)建议,在有大量产品类型的在线购物场景下,用相关的隐藏因子分解方法来灵活模拟消费者的异质性。他们利用一家中等规模的在线零售商的数据,涉及3 226种产品,在类型和品牌层面加总之后,缩减为440种产品。该研究没有分析消费者对价格变化的反应以及类似产品之间的替代,而是秉承机器学习研究的精神,通过预测消费者将购买的新产品来评估模型的表现。
不同于这种把机器学习方法直接应用于产品选择的做法,近期的研究试图把机器学习方法同经济学中关于消费者选择的观点结合起来,主要是利用面板数据。此类研究文献的一个主题是,模型中如果考虑了某些问题的结构特性,其表现会优于不考虑结构性特征的其他模型。例如,经济学中的消费者选择模型采用的函数形式带有大量结构性特征,反映了一个类型中的产品如何相互作用。比如它们决定了某个产品的价格提高会引起对其他产品的选择发生特定变化。由于这些函数形式包含的约束条件很好地模拟了现实情况,它们就能极大地改进估计的效率。因此,把数十年经济学研究已经证明非常有效的函数形式纳入考虑,可以改进模型的表现。
当然,经济学模型通常没有包含面板数据可能反映的所有信息,而矩阵填充法往往能够对此类信息加以利用。另外,计算难题妨碍了经济学家探讨多种产品类型中的消费者选择,而在现实中,消费者对一类产品的购买数据包含着对其他类产品的购买信息,而且这些数据还能揭示哪些产品会有类似的购买模式。所以,此类新混合方法的研究文献采用的优秀模型经常利用了矩阵填充法开发的技术,特别是矩阵因子分解方法。
为说明矩阵因子分解如何改进标准的消费者选择模型,我们可以把消费者i在时间t对产品j的效用表述为:
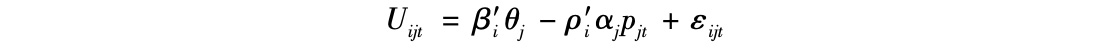 |
其中,βi,θj,ρi和αj是隐藏变量的向量。例如,向量θj可以理解为产品j的隐藏产品特征的向量,βi代表消费者i对这些特征的隐藏偏好。选择概率的基本函数形式不变,只是效用成了隐藏特征的函数。
此类模型直到最近才在机器学习文献中被采用,部分原因是选择概率的函数形式在大量隐藏参数上属于非线性,让计算变得极具挑战性。相比而言,传统的机器学习模型可以把所有产品都视作独立选择(如Gopalan et al.,2015),让计算变得简单许多。有研究(Ruiz et al.,2017)采用了机器学习中的高明计算技术,尤其是随机梯度下降和变分推断(variational inference),加上几个近似方法,使模型可以扩展到数千个消费者、每个消费者在数十到数百次购物中对数千个产品做选择的情形。该研究并未利用关于产品类型的任何数据,而是试图从产品属于替代品或互补品,并包含大量价格变化的数据中去学习。相反,阿西等人(Athey et al.,2017b)的研究纳入了关于产品类型的信息,并假设消费者在给定购物清单中对每个类型只购买一件产品。该研究还引入了嵌套逻辑结构(nested logit structure),使得效用与同一类型中的不同产品形成关联,以便更好地解释消费者是否选择购买某个类型的产品。
有的研究(Wan et al.,2017)则采用了与之密切相关的一种方法,利用包含价格差异的隐藏因子分解方法。该研究把消费者选择构建为一个三阶段过程:(a)选择是否购买某种产品类型;(b)在既定类型之中选择具体产品;(c)选择要购买的产品的数量。该研究利用了两个不同数据库的消费者忠诚度交易信息。在所有上述方法中,利用经济学的效用最大化方法,我们可以开展传统分析,如价格变化对消费者福利的影响等。对基于隐藏产品特征的研究,塞梅诺娃等人(Semenova et al.,2018)提出了一种补充方法,利用观测到的高维产品特性(如文字描述和图像),而非隐藏特征。
9.文本分析
有大量机器学习文献是针对文本数据的分析,对这个领域的充分阐述已超过了本文的范围。近期的研究综述可参见根茨科等人(Gentzkow et al.,2017)的研究。本节将提供一个高度概括的介绍。
首先我们设想有一个包含了N个文件的数据库,编号为i= 1,…,N,每个文件都包含一个词汇集合。表述该数据库的一种方式是采用N×T的矩阵,记为C,其中T是语言中使用的词汇数量,矩阵的每个元素则表示词汇t是否在文件i中出现。这种表述方式忽略了词汇在文本中的次序,会丢失信息。更丰富的表述方式是让T代表二元词串(bigram)的数量,二元词串则是在文件中彼此紧邻的一对词汇,或者三个或更多词汇组成的顺序连接。
对于此类数据,我们可以做两种类型的操作:一种是非监督学习,另一种是监督学习。对非监督学习的情形,目标是找到矩阵C的一个低秩表达式。由于如上文所述,低秩矩阵可以由因子结构矩阵来近似,这相当于找到文件的一组k个隐藏特征(标记为β)和对应的一组隐藏权重(标记为θ),使词汇t出现在文件i中的概率为函数θ′iβj。对问题的这种理解将它转化为一个矩阵填充问题,如果我们对C中的随机选择元素保留一个测试集,而模型能够很好地预测保留元素,则可以认为某个表达式的表现良好。上述矩阵填充的所有方法都可以在这种情形下得到应用。
这些理念的一种运用被称为主题模型(topic model,有关综述可参阅Blei and Lafferty,2009)。该模型是一种特定的数据生成模型,其中有若干主题,属于隐藏变量。每个主题都与词汇的分布有关,一篇文章的特征反映在每个主题的权重上。主题模型的目标是估计隐藏主题、每个主题的词汇分布以及每篇文章的权重。这方面的一种流行模型被称为隐藏的狄利克雷配置模型(latent Dirichlet allocation model)。
近期出现了更复杂的语言模型,虽然简单的机器学习模型运转不错,但把特定问题的结构纳入考虑往往能有所帮助,并可以采用在大众应用领域的高明机器学习方法。一般来说,这些被称为词汇嵌入方法(word embedding methods)。它们试图反映语言中隐藏的语义学结构。(*3.参见Mnih and Hinton(2007);Mnih and Teh(2012);Mikolov et al.(2013a,b,c);Mnih and Kavukcuoglu(2013);Levy and Goldberg(2014);Pennington et al.(2014); Vilnis and McCallum(2015);Arora et al.(2016);Barkan(2016); Bamler and Mandt(2017)。)我们来看神经概率语言模型(neural probabilistic language model)的例子,该模型设定了词汇序列的联合分布概率,利用词汇表的向量表述来实现参数化(Bengio et al.,2003,2006)。词汇的向量表述(被称为分布式表述)可以包含关于词汇的使用和意义的相关内容(Harris,1954;Firth,1957;Bengio et al.,2003;Mikolov et al.,2013b)。
另一类模型采用了监督学习方法,此类方法用于研究者希望从文本中了解到某些特征的情形。例如一篇评论的受欢迎程度、议员们讲话的政治极端程度、某家企业的推特内容的正面或负面属性等。此时,结果变量是包含了我们关注的特征的一个标签。一种简单的监督学习模型利用数据矩阵C,把每篇文件i视为一个观测单元,把矩阵C中的列(分别对应某个特定词汇是否出现在一个文件中)作为回归中的协变量。由于T通常远大于N,利用允许正则化的机器学习方法就显得非常重要。有时在应用某种监督学习方法(如非监督学习的主题模型)之前,还采用了其他类型的降维技术。
还有一种方法是借鉴生成模型。我们把文件中的词汇设想为结果向量,而且与主题模型类似,我们关注的文件特征决定了词汇的分布。这方面的例子之一是监督学习的主题模型,把训练数据库中观测到的特征信息纳入生成模型的估计。然后以被估计模型为基础,预测未标签文件的测试数据库的这些特征(更多细节参见Blei and Lafferty,2009)。
10.结论
快速发展的机器学习研究给经济学领域的实证研究者提供了大量工具。在这篇回顾文献中,我们描述了自认为对经济学家最有用的某些方法,并强烈主张将其纳入核心的计量经济学研究生课程。熟悉这些方法将帮助学者们开展更先进的实证研究,并促进与其他领域的同行们的有效交流。
(余江 译)
参考文献
Abadie A,Cattaneo MD.2018.Econometric methods for program evaluation.Annu.Rev.Econ.10:465-503.
Abadie A,Diamond A,Hainmueller J.2010.Synthetic control methods for comparative case studies:estimating the effect of California’s tobacco control program.J.Am.Stat.Assoc.105:493-505.
Abadie A,Diamond A,Hainmueller J.2015.Comparative politics and the synthetic control method.Am.J.Political Sci.59:495-510.
Abadie A,Imbens GW.2011.Bias-corrected matching estimators for average treatment effects.J.Bus.Econ.Stat. 29:1-11.
Alpaydin E.2009.Introduction to Machine Learning.Cambridge,MA:MIT Press.
Angrist JD,Pischke JS.2008.Mostly Harmless Econometrics:An Empiricist’s Companion.Princeton,NJ:Princeton Univ.Press.
Arjovsky M,Bottou L.2017.Towards principled methods for training generative adversarial networks.arXiv:1701.04862 \[stat.ML\].
Arora S,Li Y,Liang Y,Ma T.2016.RAND-WALK:a latent variable model approach to word embeddings.Trans.Assoc.Comput.Linguist.4:385-99.
Athey S.2017.Beyond prediction:using big data for policy problems.Science 355:483-85.
Athey S.2019.The impact of machine learning on economics.In The Economics of Artificial Intelligence:AnAgenda,ed.AK Agrawal,J Gans,A Goldfarb.Chicago:Univ.Chicago Press.In press.
Athey S,Bayati M,Doudchenko N,Imbens G,Khosravi K.2017a.Matrix completion methods for causal panel data models.arXiv:1710.10251 \[math.ST\].
Athey S,Bayati M,Imbens G,Zhaonan Q.2019.Ensemble methods for causal effects in panel data settings.NBER Work.Pap.25675.
Athey S,Blei D,Donnelly R,Ruiz F.2017b.Counterfactual inference for consumer choice across many product categories.AEA Pap.Proc.108:64-67.
Athey S,Imbens G.2016.Recursive partitioning for heterogeneous causal effects.PNAS 113:7353-60.
Athey S,Imbens G,Wager S.2016a.Efficient inference of average treatment effects in high dimensions via approximate residual balancing.arXiv:1604.07125 \[math.ST\].
Athey S,Imbens GW.2017a.The econometrics of randomized experiments.In Handbook of Economic Field Experiments, Vol.1,ed.E Duflo,A Banerjee,pp.73-140.Amsterdam:Elsevier.
Athey S,Imbens GW.2017b.The state of applied econometrics:causality and policy evaluation.J.Econ.Perspect.31:3-32.
Athey S,Mobius MM,Pál J.2017c.The impact of aggregators on internet news consumption.Unpublished manuscript,Grad.School Bus.,Stanford Univ.,Stanford,CA.
Athey S,Tibshirani J,Wager S.2016b.Generalized random forests.arXiv:1610.01271 \[stat.ME\].
Athey S,Wager S.2017.Efficient policy learning.arXiv:1702.02896 \[math.ST\].
Bai J.2003.Inferential theory for factor models of large dimensions.Econometrica 71:135-71.
Bai J,Ng S.2002.Determining the number of factors in approximate factor models.Econometrica 70:191-221.
Bai J,Ng S.2017.Principal components and regularized estimation of factor models.arXiv:1708.08137 \[stat.ME\].
Bamler R,Mandt S.2017.Dynamic word embeddings via skip-gram filtering.In Proceedings of the 34th International Conference on Machine Learning,pp.380-89.La Jolla,CA:Int.Mach.Learn.Soc.
Barkan O.2016.Bayesian neural word embedding.arXiv:1603.06571 \[math.ST\].
Bastani H,Bayati M.2015.Online decision-making with high-dimensional covariates.Work.Pap.,Univ.Penn./Stanford Grad.School Bus.,Philadelphia/Stanford,CA.
Bell RM,Koren Y.2007.Lessons from the Netflix prize challenge.ACM SIGKDD Explor.Newsl.9:75-79.
Belloni A,Chernozhukov V,Hansen C.2014.High-dimensional methods and inference on structural and treatment effects.J.Econ.Perspect.28:29-50.
Bengio Y,Ducharme R,Vincent P,Janvin C.2003.A neural probabilistic language model.J.Mach.Learn.Res. 3:1137-55.
Bengio Y,Schwenk H,Senécal JS,Morin F,Gauvain JL.2006.Neural probabilistic language models.In Innovations in Machine Learning:Theory and Applications,ed.DE Holmes,pp.137-86.Berlin:Springer.
Bennett J,Lanning S.2007.The Netflix prize.In Proceedings of KDD Cup and Workshop 2007,p.35.New York:ACM.
Bertsimas D,King A,Mazumder R.2016.Best subset selection via a modern optimization lens.Ann.Stat.44:813-52.
Bickel P,Klaassen C,Ritov Y,Wellner J.1998.Efficient and Adaptive Estimation for Semiparametric Models.Berlin:Springer.
Bierens HJ.1987.Kernel estimators of regression functions.In Advances in Econometrics:Fifth World Congress,Vol.1,ed.TF Bewley,pp.99-144.Cambridge,UK:Cambridge Univ.Press.
Blei DM,Lafferty JD.2009.Topic models.In Text Mining:Classification,Clustering,and Applications,ed.A Srivastava,M Sahami,pp.101-24.Boca Raton,FL:CRC Press.
Bottou L.1998.Online learning and stochastic approximations.In On-Line Learning in Neural Networks,ed.D Saad,pp.9-42.New York:ACM.
Bottou L.2012.Stochastic gradient descent tricks.In Neural Networks:Tricks of the Trade,ed.G Montavon,G Orr,K-R Müller,pp.421-36.Berlin:Springer.
Breiman L.1993.Better subset selection using the non-negative garotte.Tech.Rep.,Univ.Calif.,Berkeley.
Breiman L.1996.Bagging predictors.Mach.Learn.24:123-40.
Breiman L.2001a.Random forests.Mach.Learn. 45:5-32.
Breiman L.2001b.Statistical modeling:the two cultures (with comments and a rejoinder by the author).Stat.Sci. 16:199-231.
Breiman L,Friedman J,Stone CJ,Olshen RA.1984.Classification and Regression Trees.Boca Raton,FL:CRC Press.
Burkov A.2019.The Hundred-Page Machine Learning Book.Quebec City,Can.:Andriy Burkov.
Candeés E,Tao T.2007.The Dantzig selector:statistical estimation when p is much larger than n.Ann.Stat.35:2313-51.
Candeés EJ,Recht B.2009.Exact matrix completion via convex optimization.Found.Comput.Math.9:717.
Chamberlain G.2000.Econometrics and decision theory.J.Econom.95:255-83.
Chen X.2007.Large sample sieve estimation of semi-nonparametric models.In Handbook of Econometrics,Vol.6B,ed.JJ Heckman,EE Learner,pp.5549-632.Amsterdam:Elsevier.
Chernozhukov V,Chetverikov D,Demirer M,Duflo E,Hansen C,et al.2016a.Double machine learning for treatment and causal parameters.Tech.Rep.,Cent.Microdata Methods Pract.,Inst.Fiscal Stud.,London.
Chernozhukov V,Chetverikov D,Demirer M,Duflo E,Hansen C,et al.2018a.Double/debiased machine learning for treatment and structural parameters.Econom.J.21:C1-68.
Chernozhukov V,Chetverikov D,Demirer M,Duflo E,Hansen C,Newey W.2017.Double/debiased/Neyman machine learning of treatment effects.Am.Econ.Rev.107:261-65.
Chernozhukov V,Demirer M,Duflo E,Fernandez-Val I.2018b.Generic machine learning inference on heterogenous treatment effects in randomized experiments.NBER Work.Pap.24678.
Chernozhukov V,Escanciano JC,Ichimura H,Newey WK.2016b.Locally robust semiparametric estimation.arXiv:1608.00033 \[math.ST.\].
Chernozhukov V,Newey W,Robins J.2018c.Double/de-biased machine learning using regularized Riesz representers.arXiv:1802.08667 \[stat.ML\].
Chipman HA,George EI,McCulloch RE.2010.Bart:Bayesian additive regression trees.Ann.Appl.Stat.4:266-98.
Cortes C,Vapnik V.1995.Support-vector networks.Mach.Learn.20:273-97.
Dietterich TG.2000.Ensemble methods in machine learning.In Multiple Classifier Systems:First International Workshop,Cagliari,Italy,June 21-23,pp.1-15.Berlin:Springer.
Dimakopoulou M,Athey S,Imbens G.2017.Estimation considerations in contextual bandits.arXiv:1711.07077 \[stat.ML\].
Dimakopoulou M,Zhou Z,Athey S,Imbens G.2018.Balanced linear contextual bandits.arXiv:1812.06227.
Doudchenko N,Imbens GW.2016.Balancing,regression,difference-in-differences and synthetic control methods:a synthesis.NBER Work.Pap.22791.
Dudik M,Erhan D,Langford J,Li L.2014.Doubly robust policy evaluation and optimization.Stat.Sci.29:485-511.
Dudik M,Langford J,Li L.2011.Doubly robust policy evaluation and learning.In Proceedings of the 28th International Conference on Machine Learning,pp.1097-104.La Jolla,CA:Int.Mach.Learn.Soc.
Efron B,Hastie T.2016.Computer Age Statistical Inference,Vol.5.Cambridge,UK:Cambridge Univ.Press.
Efron B,Hastie T,Johnstone I,Tibshirani R.2004.Least angle regression.Ann.Stat.32:407-99.
Farrell MH,Liang T,Misra S.2018.Deep neural networks for estimation and inference:application to causal effects and other semiparametric estimands.arXiv:1809.09953 .\[econ.EM\].
Firth JR.1957.A synopsis of linguistic theory 1930-1955.In Studies in Linguistic Analysis (Special Volume of the Philological Society),ed.JR Firth,pp.1-32.Oxford,UK:Blackwell.
Friedberg R,Tibshirani J,Athey S,Wager S.2018.Local linear forests.arXiv:1807.11408 \[stat.ML\].
Friedman JH.2002.Stochastic gradient boosting.Comput.Stat.Data Anal. 38:367-78.
Gentzkow M,Kelly BT,Taddy M.2017.Text as data.NBER Work.Pap.23276.
Goodfellow I,Pouget-Abadie J,Mirza M,Xu B,Warde-Farley D,et al.2014.Generative adversarial nets.In Advances in Neural Information Processing Systems,Vol.27,ed.Z Ghahramani,M Welling,C Cortes,ND.Lawrence,KQ Weinberger,pp.2672-80.San Diego,CA:Neural Inf.Process.Syst.Found.
Gopalan P,Hofman J,Blei DM.2015.Scalable recommendation with hierarchical Poisson factorization.In Proceedings of the 31st Conference on Uncertainty in Artificial Intelligence,Amsterdam,Neth.,July 12-16,art.208.Amsterdam:Assoc.Uncertain.Artif.Intell.
Green DP,Kern HL.2012.Modeling heterogeneous treatment effects in survey experiments with Bayesian additive regression trees.Public Opin.Q. 76:491-511.
Greene WH.2000.Econometric Analysis.Upper Saddle River,N J:Prentice Hall.4th ed.
Harris ZS.1954.Distributional structure.Word 10:146-62.
Hartford J,Lewis G,Taddy M.2016.Counterfactual prediction with deep instrumental variables networks.arXiv:1612.09596 \[stat.AP\].
Hartigan JA,Wong MA.1979.Algorithm as 136:a k-means clustering algorithm.J.R.Stat.Soc.Ser.C 28:100-8.
Hastie T,Tibshirani R,Friedman J.2009.The Elements of Statistical Learning.Berlin:Springer.
Hastie T,Tibshirani R,Tibshirani RJ.2017.Extended comparisons of best subset selection,forward stepwise selection,and the lasso.arXiv:1707.08692 \[stat.ME\].
Hastie T,Tibshirani R,Wainwright M.2015.Statistical Learning with Sparsity:The Lasso and Generalizations.New York:CRC Press.
Hill JL.2011.Bayesian nonparametric modeling for causal inference.J.Comput.Graph.Stat. 20:217-40.
Hirano K,Porter JR.2009.Asymptotics for statistical treatment rules.Econometrica 77:1683-701.
Hoerl AE,Kennard RW.1970.Ridge regression:biased estimation for nonorthogonal problems.Technometrics 12:55-67.
Holland PW.1986.Statistics and causal inference.J.Am.Stat.Assoc. 81:945-60.
Hornik K,Stinchcombe M,White H.1989.Multilayer feedforward networks are universal approximators.Neural Netw. 2:359-66.
Imai K,Ratkovic M.2013.Estimating treatment effect heterogeneity in randomized program evaluation.Ann.Appl.Stat.7:443-70.
Imbens G,Wooldridge J.2009.Recent developments in the econometrics of program evaluation.J.Econ.Lit..47:5-86.
Imbens GW,Lemieux T.2008.Regression discontinuity designs:a guide to practice.J.Econom.142:615-35.
Imbens GW,Rubin DB.2015.Causal Inference in Statistics,Social,and Biomedical Sciences.Cambridge,UK:Cambridge Univ.Press.
Jacobs B,Donkers B,Fok D.2014.Product Recommendations Based on Latent Purchase Motivations.Rotterdam,Neth.:ERIM.
Jiang N,Li L.2016.Doubly robust off-policy value evaluation for reinforcement learning.In Proceedings of the 33rd International Conference on Machine Learning,pp.652-61.
La Jolla,CA:Int.Mach.Learn.Soc.Kallus N.2017.Balanced policy evaluation and learning.arXiv:1705.07384 \[stat.ML\].
Keane MP.2013.Panel data discrete choice models of consumer demand.In The Oxford Handbook of Panel Data,ed.BH Baltagi,pp.54-102.Oxford,UK:Oxford Univ.Press.
KitagawaT,TetenovA.2015.Who should be treated?Empirical welfare maximization methods for treatment choice.Tech.Rep.,Cent.Microdata Methods Pract.,Inst.Fiscal Stud.,London.
Knox SW.2018.Machine Learning:A Concise Introduction.Hoboken,NJ:Wiley.
Krizhevsky A,Sutskever I,Hinton GE.2012.Imagenet classification with deep convolutional neural networks.In Advances in Neural Information Processing Systems,Vol.25,ed.Z Ghahramani,M Welling,C Cortes,ND Lawrence,KQ Weinberger,pp.1097-105.San Diego,CA:Neural Inf.Process.Syst.Found.
Künzel S,Sekhon J,Bickel P,Yu B.2017.Meta-learners for estimating heterogeneous treatment effects using machine learning.arXiv:1706.03461 \[math.ST\].
Lai TL,Robbins H.1985.Asymptotically efficient adaptive allocation rules.Adv.Appl.Math. 6:4-22.
LeCun Y,Bengio Y,Hinton G.2015.Deep learning.Nature 521:436-44.
Levy O,Goldberg Y.2014.Neural word embedding as implicit matrix factorization.In Advances in Neural Information Processing Systems,Vol.27,ed.Z Ghahramani,M Welling,C Cortes,ND Lawrence,KQ Weinberger,pp.2177-85.San Diego,CA:Neural Inf.Process.Syst.Found.
Li L,Chen S,Kleban J,Gupta A.2014.Counterfactual estimation and optimization of click metrics for search engines:a case study.In Proceedings of the 24th International Conference on the World Wide Web,pp.929-34.New York:ACM.
Li L,Chu W,Langford J,Moon T,Wang X.2012.An unbiased offline evaluation ofcontextual bandit algorithms with generalized linear models.In Proceedings of 4th ACM International Conference on Web Search and Data Mining, pp.297-306.New York:ACM.
Matzkin RL.1994.Restrictions of economic theory in nonparametric methods.In Handbook of Econometrics,Vol.4,ed.R Engle,D McFadden,pp.2523-58.Amsterdam:Elsevier.
Matzkin RL.2007.Nonparametric identification.In Handbook of Econometrics,Vol.6B,ed.J Heckman,E Learner,pp.5307-68.Amsterdam:Elsevier.
Mazumder R,Hastie T,Tibshirani R.2010.Spectral regularization algorithms for learning large incomplete matrices.J.Mach.Learn.Res.11:2287-322.
Meinshausen N.2007.Relaxed lasso.Comput.Stat.Data Anal.52:374-93.
Mikolov T,Chen K,Corrado GS,Dean J.2013a.Efficient estimation of word representations in vector space.arXiv:1301.3781 \[cs.CL\].
Mikolov T,Sutskever I,Chen K,Corrado GS,Dean J.2013b.Distributed representations of words and phrases and their compositionality.In Advances in Neural Information Processing Systems,Vol.26,ed.Z Ghahramani,M Welling,C Cortes,ND Lawrence,KQ Weinberger,pp.3111-19.San Diego,CA:Neural Inf.Process.Syst.Found.
Mikolov T,Yih W,Zweig G.2013c.Linguistic regularities in continuous space word representations.In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,pp.746-51.New York:Assoc.Comput.Linguist.
Miller A.2002.Subset Selection in Regression.New York:CRC Press.
Mnih A,Hinton GE.2007.Three new graphical models for statistical language modelling.In International Conference on Machine Learning,pp.641-48.La Jolla,CA:Int.Mach.Learn.Soc.
Mnih A,Kavukcuoglu K.2013.Learning word embeddings efficiently withnoise-contrastive estimation.In Advances in Neural Information Processing Systems,Vol.26,ed.Z Ghahramani,M Welling,C Cortes,ND Lawrence,KQ Weinberger,pp.2265-73.San Diego,CA:Neural Inf.Process.Syst.Found.
Mnih A,Teh YW.2012.A fast and simple algorithm for training neural probabilistic language models.In Proceedings of the 29th International Conference on Machine Learning,pp.419-26.La Jolla,CA:Int.Mach.Learn.Soc.
Morris CN.1983.Parametric empirical Bayes inference:theory and applications.J.Am.Stat.Assoc.78:47-55.
Mullainathan S,Spiess J.2017.Machine learning:an applied econometric approach.J.Econ.Perspect.31:87-106.
Nie X,Wager S.2019.Quasi-oracle estimation of heterogeneous treatment effects.arXiv:1712.04912 \[stat.ML\].
Pennington J,Socher R,Manning CD.2014.GloVe:global vectors for word representation.In Proceedings of the 2014 Conference on Empirical Methods on Natural Language Processing,pp.1532-43.New York:Assoc.Comput.Linguist.
Robins J,Rotnitzky A.1995.Semiparametric efficiency in multivariate regression models with missing data.J.Am.Stat.Assoc.90:122-29.
Rosenbaum PR,Rubin DB.1983.The central role of the propensity score in observational studies for causal effects.Biometrika 70:41-55.
Ruiz FJ,Athey S,Blei DM.2017.SHOPPER:a probabilistic model of consumer choice with substitutes and complements.arXiv:1711.03560 \[stat.ML\].
Rumelhart DE,Hinton GE,Williams RJ.1986.Learning representations by back-propagating errors.Nature 323:533-36.
Schapire RE,Freund Y.2012.Boosting:Foundations and Algorithms.Cambridge,MA:MIT Press.
Scholkopf B,Smola AJ.2001.Learning with Kernels:Support Vector Machines,Regularization,Optimization,and Beyond.Cambridge,MA:MIT Press.
Scott SL.2010.A modern Bayesian look at the multi-armed bandit.Appl.Stoch.Models Bus.Ind.26:639-58.
Semenova V,Goldman M,Chernozhukov V,Taddy M.2018.Orthogonal ML for demand estimation:high dimensional causal inference in dynamic panels.arXiv:1712.09988 \[stat.ML\].
Strehl A,Langford J,Li L,Kakade S.2010.Learning from logged implicit exploration data.In Advances in Neural Information Processing Systems,Vol.23,ed.Z Ghahramani,M Welling,C Cortes,ND Lawrence,KQ Weinberger,pp.2217-25.San Diego,CA:Neural Inf.Process.Syst.Found.
Sutton RS,Barto AG.1998.Reinforcement Learning:An Introduction.Cambridge,MA:MIT Press.
Swaminathan A,Joachims T.2015.Batch learning from logged bandit feedback through counterfactual risk minimization.J.Mach.Learn.Res. 16:1731-55.
Thomas P,Brunskill E.2016.Data-efficient off-policy policy evaluation for reinforcement learning.In Proceedings of the International Conference on Machine Learning,pp.2139-48.La Jolla,CA:Int.Mach.Learn.Soc.
Thompson WR.1933.On the likelihood that one unknown probability exceeds another in view of the evidence of two samples.Biometrika25:285-94.
Tibshirani R.1996.Regression shrinkage and selection via the lasso.J.R.Stat.Soc. 58:267-88.
Tibshirani R,Hastie T.1987.Local likelihood estimation.J.Am.Stat.Assoc.82:559-67.
van der Laan MJ,Rubin D.2006.Targeted maximum likelihood learning.Int.J.Biostat. 2(1):34-56.
Van der Vaart AW.2000.Asymptotic Statistics.Cambridge,UK:Cambridge Univ.Press.
Vapnik V.2013.The Nature of Statistical Learning Theory.Berlin:Springer.
Varian HR.2014.Big data:new tricks for econometrics.J.Econ.Perspect.28:3-28.
Vilnis L,McCallum A.2015.Word representations via Gaussian embedding.arXiv:1412.6623 \[cs.CL\].
Wager S,Athey S.2017.Estimation and inference of heterogeneous treatment effects using random forests.J.Am.Stat.Assoc.113:1228-42.
Wan M,Wang D,Goldman M,Taddy M,Rao J,et al.2017.Modeling consumer preferences and price sensitivities from large-scale grocery shopping transaction logs.In Proceedings of the 26th International Conference on the World Wide Web,pp.1103-12.New York:ACM.
White H.1992.Artificial Neural Networks:Approximation and Learning Theory.Oxford,UK:Blackwell.
Wooldridge JM.2010.Econometric Analysis of Cross Section and Panel Data.Cambridge,MA:MIT Press.
Wu X,Kumar V,Quinlan JR,Ghosh J,Yang Q,et al.2008.Top 10 algorithms in data mining.Knowl.Inform.Syst.14:1-37.
Zeileis A,Hothorn T,Hornik K.2008.Model-based recursive partitioning.J.Comput.Graph.Stat. 17:492-514.
Zhou Z,Athey S,Wager S.2018.Offline multi-action policy learning:generalization and optimization.arXiv:1810.04778 \[stat.ML\].
Zou H,Hastie T.2005.Regularization and variable selection via the elastic net.J.R.Stat.Soc.B 67:301-20.
Zubizarreta JR.2015.Stable weights that balance covariates for estimation with incomplete outcome data.J.Am.Stat.Assoc. 110:910-22.

















{kind=link}